
MongoDB 事务,复制和分片的关系
1.前言
- MongoDB基于wiredTiger提供的泛化SI的功能,重构了readHistory(readMajority)的能力
- 基于wiredTiger提供的AllCommittedTimestamp API,重构了前缀一致的主从复制(Prefix-Consistent-Replication)
- 引入混合逻辑时钟(HLC),每个节点(Mongos/Mongod)的逻辑时钟维持在接近的值,基于此实现ChangeStream, 结合HLC与CLOCK-SI,实现分布式事务,HLC和泛化SI,CLOCK-SI两篇Paper可以作为理解MongoDB的设计的理论参考(这里并没有说MongoDB是Paper的实现)。
本文尝试对Mongo的复制和分布式事务的原理进行描述,在必要的地方,对实现的正确性进行论证,希望能为MongoDB内核爱好者提供一些参考。
2.MongoDB副本集事务介绍
- MongoDB 副本集的事务
- MongoDB副本集的复制是基于raft协议,相比于Paxos,raft协议实现简单,但是raft协议只支持single-master,对应的,MongoDB的副本集是主从架构,而且只有主节点支持写入操作。MongoDB副本集的事务管理,包括冲突检测,事务提交等关键操作,都只在主节点上完成。也就是说副本集的事务在事务管理方面,跟单节点逻辑基本一致。
- MongoDB的事务,仍然是实现了 ACID 四个特性, MongoDB使用 SI 作为事务的隔离级别。
3.SI的简介
- SI,即SnapshotIsolation,中文称为快照隔离,是一种mvcc的实现机制,它在1995年的A Critique of ANSI SQL Isolation Levels中被正式提出。因快照时间点的选取上的不同,又分为Conventional Si 和 Generalized SI。
CSI(Convensional SI)
- CSI 选取当前最新的系统快照作为事务的读取快照
- 就是在事务开始的时候,获得当前db最新的snapshot,作为事务的读取的snapshot,
- snapshot(Ti) = start(Ti)
- 可以减少写事务冲突发生的概率,并且提供读事务读取最新数据的能力
- 一般我们说一个数据库支持SI隔离级别,其实默认是说支持CSI。比如RocksDB支持的SI就是CSI,WiredTiger在3.0版本之前支持的SI也是CSI。
GSI(Generalized SI)
- GSI选择历史上的数据库快照作为事务的读取快照,因此CSI可以看作GSI的一个特例。
- 在复制集的情况下,考虑 CSI, 对于主节点上的事务,每次事务的开始时间选取的系统 最新的 快照, 但是对于其他从节点来说, 并没有 统一的 “最新的” 快照这个概念。泛化的快照实际上是基于快照观测得到的,对于当前事务来说,我们通过选取合适的 更早时间的快照,可以让 从节点上的事务正确且无延迟的执行。
- 举例如下:
- 例如当前数据库的状态是, S={T1, T2, T3}, 现在要开始执行T4,
- 如果我们知道T4要修改的值,在T3上没有被修改, 那么我们在执行T4的时候, 就可以按照 T2 commit后的snashot进行读取。
- 如何选择更早的时间点,需要满足下面的规则,

- 符号定义
- Ti: 事务i
- Xi: 被事务i修改过的X变量
- snapshot(Ti): 事务i的选取的快照时间
- start(Ti): 事务i的开始时间
- commit(Ti): 事务i的提交时间
- abort(Ti): the time when Ti is aborted.
- end(Ti): the time when Ti is committed or aborted.
公式解释
读规则
- G1.1, 如果变量X被本事务修改了值且读取到了新的值, 那么 读操作一定在写操作后面;
- G1.2, 如果事务i读取了事务j更新的变量的X, 那么一定不会有事务i更新X的操作,在事务i读取了事务j更新的变量的X这个操作前面;
- G1.3, 事务j的提交时间早于事务i的快照时间;
- G1.4, 对于任意一个会更新变量X的事务k, 那么这个事务k一定满足, 要么事务k的提交时间小于事务j, 要么这个事务k的提交时间大于事务i。
写规则
- G2, 对于任意已经在提交历史里的两个事务,Ci, Cj, 那么一定可以保证当 事务j的commit时间戳在 事务i的观测时间段内时(snapshot(Ti), commit(Ti)), 那么他们更新的变量交集一定为空。
PCSI(PREFIX-CONSISTENT SNAPSHOT ISOLATION SI)
- GSI 只是定义了一个范围的range,都可以作为SI使用,并没有定义具体应该选择哪个SI。
- PCSI 是为了复制集而设计的。对于一个事务Ti 要开S节点开始运行, 那么 S节点将必须包含这个事务所需要的所有前置事务都必须运行且提交。
- 相比较于GSI, PCSI的读规则,额外增加了 P1.5 规则。


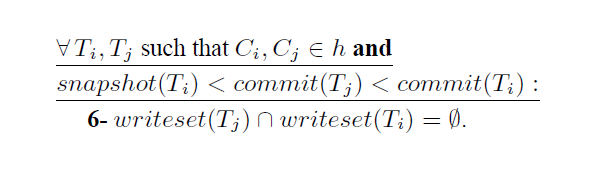
- SI的提交时间戳设置,依据 A Critique of ANSI SQL Isolation Levels 中的描述, 提交时间戳的设置应该是单调递增的。新设置的时间戳,应该大于系统中已经存在的开始时间戳和提交时间戳。
- SI 读取时间戳的设置,必须保证比当前系统中正在运行的事务的最小的提交时间戳还要小, 因为一旦大于当前系统中正在运行事务的最小的提交时间戳,那么这个读事务读取到的数据就是未定义的, 取决于读事务启动的时间,而不是snapshot的时间,这违背了 一致性的要求。举例如下
- 当前已经完成的事务是T1,正在运行的事务是T2, 将要运行的读事务是T3, 如果 T3的读时间戳大于T2事务提交时间戳, 并且T2事务正在运行,等到T2事务执行完后。我们观察这个 database,就会发现 他违背了GSI,
事务执行顺序如下所示是:
T1 commited and commitTs(1) -> T2 start -> T2 set commitTs(2) -> T3 start -> T3 set snapshotTs(3) -> T3 commit -> pointA -> T2 commit -> pointB
那么可知, T3事务实际读取的值是 T1事务的值。但根据 pointB 点来看 GSI的读规则 1.4 的要求,会发现, 如果T3读到T1的事务的修改,那么必然要求, T3和T1之间没有空洞。但实际上 T2 是落在了 T3和T1之间的, 也就是说, 违反了 GSI 1.4的读规则。
- 所以我们必须规定, SI 读取时间戳的设置,必须保证比当前系统中正在运行的事务的最小的提交时间戳还要小。
4.MongoDB副本集时间戳应用
MongoDB 4.0的复制也是利用时间戳特性解决了3.x系列MongoDB从节点复制造成从节点性能下降的关键方案。
- MongoDB oplog 乱序问题
- MongoDB主备节点的数据同步并不基于WiredTiger的wal日志来做的。相反,mongodb会将每次操作的数据变更写入到一个叫做oplog的集合里。
- oplog这个集合,虽然名字带有log,但实际上,它是一个MongoDB的表, 对oplog的写入,并不是 append的方式修改的, 而是呈现出一种尾部乱序的方式。
- 对于oplog来说, oplog的读取顺序是按照TS字段来排序的, 跟上层的提交顺序无关。所以存在后开始的事务,在oplog先读取的场景。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java