
大数据处理工具汇总
Apache Hadoop
Hadoop项目下包含了很多子项目,从计算到存储都有,比如HDFS、MapReduce、YARN、HBase。
HDFS全称叫做Hadoop分布式文件系统,其主要由一个NameNode(NN)和多个DataNode(DN)组成,数据文件会分成多个Block,这些Block按照不同主机,不同机架的策略以默认一备三的情况分布存储在各个节点。现在每个Block大小默认是128MB,以后随着磁盘寻址速度的增加,这个Block也会不断增大。而NN里面则存储了这些Block元数据的信息,这样客户端进行数据查询的时候,DN告知所需数据的位置。从这种结构上能看出一些比较明显的问题就是NN节点的单点问题,所以在Hadoop 2.x的时候,针对NN做了一些改进。
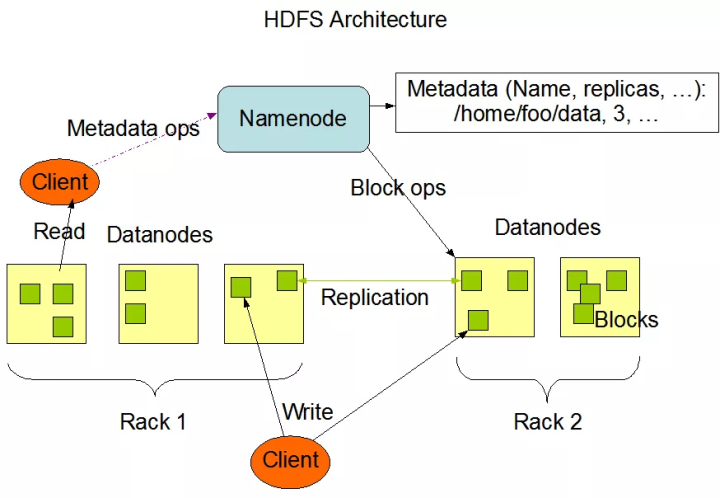
首先是在系统可用性上,增加了一个StandBy状态的NN,作为服务中NN(Active NN)的备机,当服务中的NN挂掉后,由StandBy的NN自动接替工作。而NN节点状态的健康和服务切换,由ZKFC负责。主备NN之间的信息同步则由Quorum Journal Node负责。
其次,由于单台NN中存储了大量的元数据信息,所以随着HDFS数据量的不断增加,显然NN必将成为系统的瓶颈,为了解决这个问题,Hadoop 2.x增加了Federation,该技术允许系统中有多台NN同时对外提供服务,这多台NN将DN中的所有文件路径进行了横向拆分,每个DN负责不同的路径,达到了横向扩展的效果。
除了HDFS,Hadoop 2.x也引入了YARN,该工具负责对集群中的资源进行管理和任务的协调。该工具分成一个ResourceManager(RM)和多个NodeManager(NM),当一个任务提交给YARN之后,会先在某一服务器上启动一个ApplicationMaster(AM),AM向RM申请资源,RM通过NM寻找集群中空闲的资源,NM将资源打包成一个个Container,交给AM。AM将数据和程序分发到对应节点上处理,如果某个Container中的任务执行失败了,AM会重新向RM申请新的Container。
Apache Hadoop HBase & Kudu
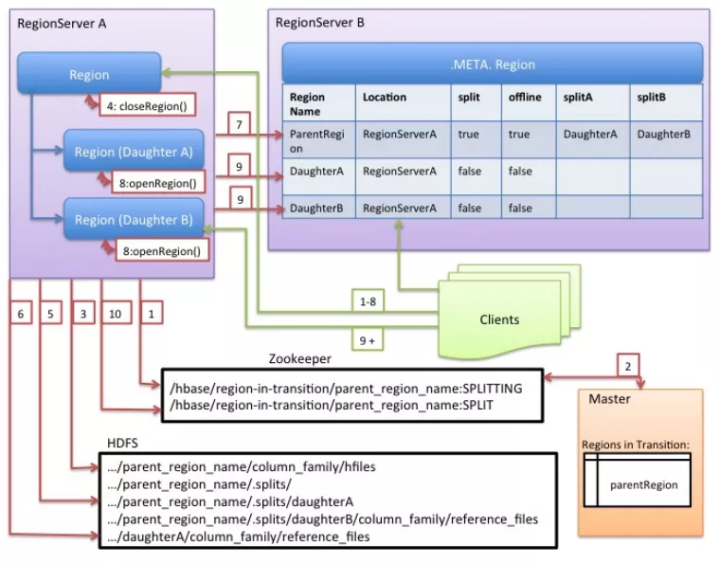
众所周知,HBase一个分布式列式存储系统,同样属于Hadoop的子项目,列式存储的优劣在这里不说了,提一下HBase的WAL和LSM,WAL全称为Write Ahead Log,只是在数据修改操作前,会先将此操作记录在日志中,这样一旦服务崩溃,通过该日志即可进行数据的恢复,提到这里有些人就会联想到MySQL,因为InnoDB引擎的redo log就是典型的WAL应用。而在HBase中该功能是由叫做HLog的模块所完成的。再说LSM,其全称为Log Structured Merge Trees,介绍原理的文章也有很多,在HBase中,LSM树是MemStore模块的底层存储结构,而MemStore有三个作用,一是当有数据写入的时候,直接写到MemStore中,从而提升写数据的效率。二是充当读取数据时的缓存。三是定期对数据操作去重,并进行数据落盘。HBase的主要角色分别有HMaster和HRegionServer,同样是一对多的关系,而各节点的状态全都交由Zookeeper负责。Kudu是一个和HBase非常类似的产品,其不同之处在于Kudu不依赖Zookeeper来管理自己的集群,并且HBase的数据是保存在HDFS上的,而Kudu拥有自己的数据文件格式。
Apache Spark
Spark是由加州大学伯克利分校推出的分布式计算引擎,在Spark的官方主页上有一张和Hadoop的性能对比图,姑且不谈这张图中数据的准确性,但是Spark的确将Hadoop(主要是指MapReduce)的性能提升了一个量级。我理解这主要得益于两个方面:第一个是Spark计算过程中生成的中间数据不再落盘,没有了Spill的阶段。第二个是引入DAG对任务进行拆解,一个完整的Job被分成多个Stage,每个Stage里面又有多个Task,通过一张有向无环图,使得没有依赖关系的Task可以并行运行。
Spark不只是在批处理上有所成绩,而是更加注重整个生态圈的建设,其拥有流式处理框架SparkStreaming,采用微批的形式达到类似流处理的效果,现在又推出了Structured Streaming,实现基于状态的流处理框架。此外还拥有SparkSQL来帮助非开发人员更加便捷的调用Spark的服务和Spark MLlib这个机器学习库。
Spark虽好,但其对内存资源消耗也很大,同时也使得他在稳定性上不如MapReduce,所以有些大公司数仓的日常任务仍旧采用传统MapReduce的方式执行,不求最快,但求最稳。我们的系统在刚从MapReduce上切到Spark时,每天夜里也是任务异常频发,最后调整了任务和资源分配,再加上一个很粗暴的重试机制解决了。
Apache Flink
Flink是德国Data Artisans公司开发一款分布式计算系统,该公司于19年初被阿里巴巴集团收购。包括Spark和Kafka,也都看到了未来流式计算的前景是非常巨大的,纷纷建立属于自己的流式计算生态圈。
Flink和Spark Streaming相比,前者是真正的流式计算,而后者是微批处理,虽然批次足够小,但其本质毕竟还是批处理,这就导致有些场景SparkStreaming注定无法满足,虽然Spark现在将重心转移到了Structured Streaming,它弥补了Spark Streaming很多的不足,但是在处理流程上仍然是微批处理。
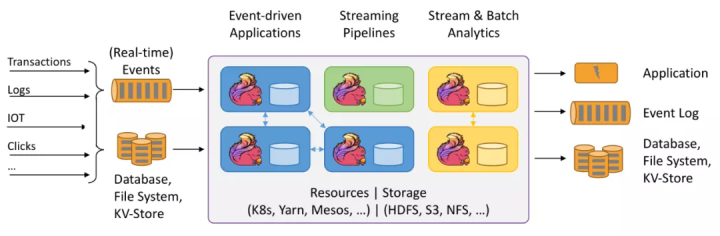
而Flink在设计之初就同时考虑了批处理和流处理这两种需求,所以使用者也可以只通过一个计算引擎,就能实现批处理和流处理两种计算场景,其主要几个需要清楚的特性我觉得分别是:State状态管理,CheckPoint容错机制,Window滑动窗口,和Watermark乱序解决。这些内容网上都有很多介绍,不再阐述。
Apache Impala
Impala是Cloudera公司用C++开发的支持SQL语义的查询系统,可以用来查询HDFS、HBase、Kudu的内容,也支持多种序列化和压缩格式,因为也是基于内存的计算,比传统MapReduce快很多。不过因为已经使用了Spark,所以组里并没有对Impala进行大规模的应用。经过一些零散的调研和了解,好像其它公司对Impala的应用也不是非常多。
Apache Zookeeper
官网:https://zookeeper.apache.org/
Zookeeper无论在数据系统还是在其它后端系统的使用场景都非常广,它可以用作分布式锁服务,可以用做系统的配置中心,可以协助完成一致性算法的选主过程,可以用于ZKFC做节点健康情况的探查,总之用处还有很多。而它的工作机制,基本就是ZAB协议的机制,一个支持崩溃恢复的原子广播协议,其主要组成也是由一个Leader和多个Follower组成的,数据的提交遵循2PC协议。当Leader崩溃时,Follower会自动切换状态开始重新选主,重新选完之后再进行多节点的数据对齐。
Apache Sqoop
一款用于在传统关系型数据库和HDFS之间互相进行数据传递的工具,无论是import还是export都提供了大量的参数,因为是分布式执行,数据传输的速度也非常快。只是在使用的过程中需要注意数据源中的异常数据,会比较容易造成数据传递过程中的异常退出。为了弥补Sqoop的功能单一,推出了Sqoop 2,架构上比Sqoop 1复杂了很多,不过我没有用过。
Apache Flume
分布式数据传输工具,支持包含文件、Netcat、JMS、HTTP在内的多种数据源。其结构上分成Source、Channel、Sink三部分,Source将获取到的数据缓存在Channel中,这个Channel可以是文件,可以是内存,也可以使用JDBC,Sink从Channel消费数据,传递给系统中的其他模块,比如HBase、HDFS、Kafka等等。
Apache Kafka
曾经是一款由Scala开发的分布式消息队列产品,现在生态已经扩展了,因为它推出了Kafka Streaming,所以现在也应该被称作是一个流处理平台了,但这里不说Kafka Streaming,因为没有用过和了解过。
Kafka的队列按照Topic划分,每个Topic下由多个Partition组成,在单个Partition中的消息保证是有序的。这种结构下确保了消息是在磁盘顺序写入的,节省了磁盘寻址的时间,所以数据落盘的速度非常快。加之采用了mmap的方式,减少了用户态和内核态之间的数据拷贝次数,mmap是一种将文件内容和内存地址映射的技术,提效十分明显。Kafka和Flume的配合使用,形成了流式处理领域里的经典框架。
Apache Ranger & Sentry
官网:http://ranger.apache.org/
官网:http://sentry.apache.org/
Ranger和Sentry都是分布式的数据安全工具,这两个产品的功能也基本是一样的,就是去管理大数据计算生态圈产品的权限,Sentry是采用插件的形式,将自己集成到Impala、Hive、HDFS、Solr等产品上,当用户向这些产品发起请求,产品会先向Sentry Server进行校验,Sentry也可以和Kerberos配合使用,从而完成跨平台统一权限管理。而Ranger所提供的功能也类似,但是所支持的产品更加多样,包括HDFS、HBase、Hive、YARN、Storm、Solr、Kafka、Atlas等,其同样也是采用一个Ranger Admin连接多个集成到产品上的Ranger插件完成的权限验证过程。
Apache Atlas
Apache Atlas是数据治理体系中比较重要的一个产品,它主要负责元数据的管理,这个元数据就是指用来描述数据的数据,比如数据的类型、名称、属性、作用、生命周期、有效范围、血缘关系等等,在大数据系统中,元数据有着非常大的价值,一个比较成熟的数据系统中一般都会存在着这么一个元数据管理平台,元数据除了能让业务人员更加方便快捷理解我们的数据和业务,也有着帮助我们提升数据质量,消除信息不对称,以及快速定位数据问题等作用,所以如何有效的利用好这些元数据,使这些数据产生更大的价值,也是很多人一直在思考的事情。现在Atlas支持的数据源有Hive、Sqoop、Storm,其导入方式有HOOK和Batch两种方式,首次使用是Batch的同步方式,之后Atlas会利用HOOK主动获取到数据源的变化,并更新自身数据。
Apache Kylin
Kylin是一个为OLAP场景量身定制的分布式数据仓库产品,提供多维分析的功能,并可以和很多BI分析工具无缝对接,比如Tableau、Superset等。Kylin提供了前端平台,使用者可以在该平台上去定义自己的数据维度,Kylin会定时完整分析所需数据的预计算,形成多个Cube,并将之保存在HBase中,所以部署Kylin的时候需要HBase环境的支持。在数据与计算的时候,对其所在设备的资源消耗也比较大。
Apache Hive & Tez
官网:https://hive.apache.org/
官网:https://tez.apache.org/
Hive应该是最有名气的数据仓库工具了吧,他将HDFS上的数据组织成关系型数据库的形式,并提供了HiveSQL进行结构化查询,使得数据分析人员可以从传统的关系型数据库几乎无缝的过渡到HDFS上,但其个别函数和传统SQL还是有区别的,并且默认也不支持update和delete操作。但开发人员可以开发UDF,为HiveSQL扩充属于自己的功能函数。Hive本身的计算是基于MapReduce的,后来为了应对SparkSQL的出现,开发组推出了Hive on Spark,使得SQL的解释、分析、优化还是在Hive上,而执行阶段交由Spark去完成,从而以达到和SparkSQL近似的速度。
Tez是对Hive的另一项优化,为其引入了DAG的概念,增加任务并行度从而提升Hive的查询速度,但其本质仍旧是MapReduce,所以提升效果相比Hive on Spark来讲并不足够明显。
Apache Presto
Presto是由facebook公司开发的一款分布式查询引擎,其主要特点是支持了非常多的Connector,从而实现在一个平台上连接多个数据源,并且可以将这些数据源的内容进行聚合计算,同时Presto也支持使用者自行开发新的Connector。并且Presto的计算过程全程是基于内存的,所以速度也是非常的快,但其实Presto也只是针对个别计算场景的性能优化会非常明显,网上有非常详细的分析文章。之前使用该工具是为了将离线数仓和实时数仓的数据进行联合查询,提供给实时数据平台使用。
在使用过程中我觉得有点不好的地方有三点。一是因为Presto基于内存计算,所以在资源紧张的情况下经常Crash导致任务失败。二是Presto任务为串行提交,所以会出现大任务阻塞小任务的情况出现。或许通过调参可以解决该问题吧,但没有再深入调研了。三是没有找到一个比较好的Web平台去查询Presto,网上有Hue通过PostgreSQL去链接Presto的方案,觉得有点麻烦,看上去比较成熟的Airpal平台也已不再更新了。最后使用了yanagishima,基本功能可以满足,但该平台没有用户管理功能,没法控制权限。
Apache Parquet & Orc
官网:https://parquet.apache.org/
官网:https://orc.apache.org/
Parquet和ORC是两种比较应用比较多的列式存储格式,列式存储不同于传统关系型数据库中行式存储的模式,这种主要的差别可能由于联机事务处理(OLTP)和联机分析处理(OLAP)的需求场景不同所造成的。在OLTP场景多是需要存储系统能满足快速的CRUD,这种操作对象都是以行为单位的。而在OLAP场景下,主要的特征是数据量巨大,而对实时性的要求并不高。而列式存储正式满足了这一需求特征。因为当数据以列的方式存储,在查询的时候引擎所读取的数据量将会更小,而且同一列的数据往往内容类似,更加便于进行数据压缩,但列式存储不适于更新和删除频繁的场景。Parquet和Orc同为列式存储,但他们的存储格式并不相同,这种差异造成了两者在存储不同类型的数据时所出现的性能差异,从网上的一些文章看,Orc的性能要比Parquet好一点,但是Impala是不支持Orc的,并且诸如Delta Lake这种数据湖产品,也是基于Parquet去做的。所以在选择采用哪种列式存储格式时,还是要根据自身的业务特点来决定。
Apache Griffin
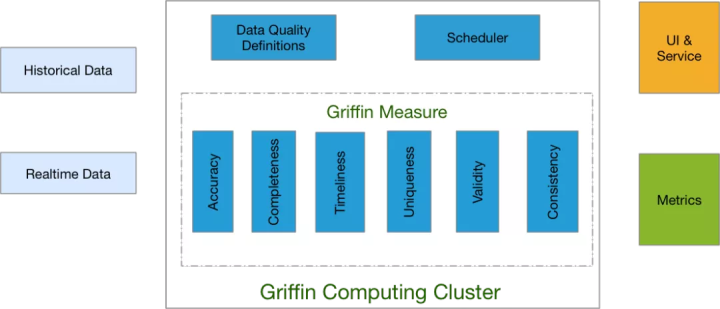
数据质量管理是数据系统中不可或缺的一环,初期的时候我们往往在ETL的各个阶段,加入一些简单的脚本来对生成的数据进行检查,而Apache Griffin也是一款这样的产品,它是由eBay开发的一个数据质量监控平台,后上升为Apache顶级项目。它提供了数据校验和报警的功能,也支持一些参数的可视化展现,相关的配置步骤都可以在Griffin的页面上完成。除了能完成一些最基本最简单的诸如是否存在异常值的数据检查,也能完成一些诸如最值、中值的数据统计需求等等,并且提供了专业的图表报告。
Apache Zeppelin
官网:http://zeppelin.apache.org/
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java