
谈谈机器学习入门
基本知识篇
这里不是让你从新去啃线性代数,去看概率论、微积分的书,当然啃下来肯定是有帮助,但我们从效率的角度来说,其实只需要几个知识点,或者说,书本里的几个章节。
理论知识重点看:微积分:multi-variable的求导,概率论:贝叶斯、高斯函数,行有余力把高维高斯了解一下,线性代数:熟悉矩阵乘法。(3-5天)
工程知识:Python
经典模型篇
掌握 classification、regression、clustering的任务目标。学习方式:比如classification,我们先要了解他的功能,观察他的输入和输出:很直观,分类任务,输入特征,输出标签。那么我们思考一个例子,看(编)一组数据:
身高 体重 性别
177 80 男
172 70 男
165 55 女
155 45 女
174 60 女
在这一组数据里,身高和体重是特征,性别是标签。我们要基于给定的数据,训练一个分类模型,在性别数据缺失的情况下,能够预测性别。待预测数据:
身高 体重
175 65
165 55
当然实际的数据规模会比这个大,这里只是作为一个示例。那么有哪些经典的分类模型呢?我们看一下这个cheat sheet。
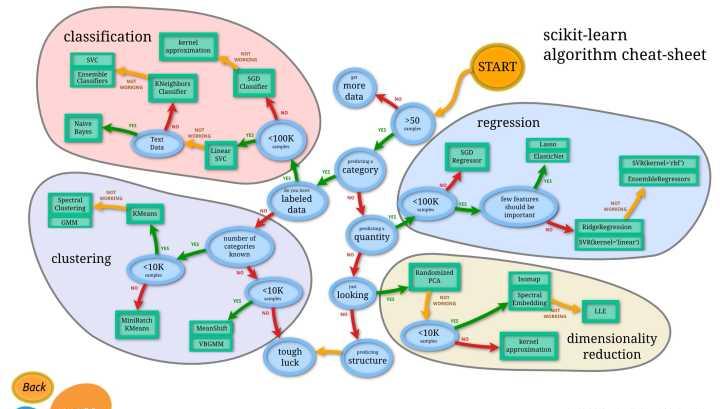 经典框架sklearn的cheat sheet
经典框架sklearn的cheat sheet
图有点被知乎压缩了,经典的模型有:SVC,线性模型,贝叶斯、KNN等等,基于不同的数据量以及数据特点我们选取不同的模型。我们这里使用SVM来示范。在把数据灌入模型之前,我们先要处理数据,把数据变成“模型可以理解”的形式。
那么这里我们首先把标签数字化:
map = {'男': 0, '女':1}那么数据的实现如下
from sklearn import svm
X = [[177 ,80], [172 ,70], [165, 55], [155, 45], [174, 60]]
y = [0, 0, 1, 1, 1]
clf = svm.SVC()
clf.fit(X, y)
#预测
clf.predict([[175, 65], [165, 55]])好的,这样你已经完成了你的第一个(非常丑陋的)机器学习模型了。对于聚类和回归问题,也是类似的,有很多经典的数据集,当然也可以自己给自己出题。
简单的入门的话,建议的次序是:1. 基于数据特点选择模型,2. 按照模型需求处理数据 3.调包实现 4. 评估模型成果,如果效果不好,换一个;对于成功的模型,研究背后的底层原理。
进阶
进到这里的同学说明已经有一定的基础,那么进阶的建模意味着:需要掌握一些进阶的模型,进阶的数据处理的方式,进阶的模型优化能力。
进阶的模型,决策树(GBDT),DNN(包括CNN,LSTM等等),甚至需要更多能够个性化的框架(tensorflow,pytorch)
进阶的数据处理:数据的分布分析,数据的分桶、归一化,categorical(阑珊化数据)和continuous(连续数据)的处理(one hot 编码),甚至结合业务进行一些操作。
模型优化:调参技巧(手动),k-fold,,参数组合(自动化暴力),模型选择等。
举例:
仍然是预测性别的问题。
我们观察一下,特征的分布,比如身高,我们先可视化一下,做个直方图
那么我们大概可以知道数据的一些特征:集中分布在155~180,其他的一些statistics(统计学特征),比如均值,标准差,25 percentile等等,都可以算一遍。根据数据的分布模式,我们可以对数据这样处理,把155~180做成一个0~1的映射,将数据做一个归一化(这里同学可以复习一下归一化带来的优点)。
那么我们还可以做一些其他分析,来帮助我们理解数据:比如做一个单特征的回归,查看某个特征和标签的相关性;特征两两之间的相关性,指导我们怎么做特征交叉;variance 分析,指导数据分桶等等。
实战
那么工业界,尤其是大厂的实际项目是啥样?我说几个大家感受一下风格。比如:
- 某新闻网站需要对新闻进行分类(体育、政治、blabla),目前没有标记数据,请问怎么解决。
2. 某电商网站需要对商品购买页的个性化商品联想推荐,希望推翻之前单纯的item-to-item的协同过滤做法,请问怎么解决。
3. 某短视频应用一直在用视频的标题和up主输入的内容来做视频特征,是否可以基于视频内容来做特征,请问怎么解决。
以上几个都是我个人给出过实际有效的解决方案的工业界实际问题,可以看出,风格上更偏向于综合性的,跨领域的问题,看官们到这里可以先停下来思考几分钟,再往下翻看答案,看看和我的solution有什么不同。
我们着重说一下第一条,大家可以看出来,这是一个开放性的问题,并没有特定的方案,在企业里,我们考虑的是:实现成本和效果指标(metrics) 的平衡。那么我们这里的metrics是什么呢?我们很显然希望分类尽量准确。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java