
合理设计系统的错误编码。
一 前言
在工作中,接触过不少外部接口,其中包括:支付宝,微信支付,微博开发平台,阿里云等等。每家公司错误码风格都不尽相同,有使用纯数字的,有使用纯英文的,也有使用字母和数字组合的。也接触过很多内部系统,错误码设计也不尽相同。
错误码的输出路径
面向日志输出
- 服务内传递,最终是输出到日志。
- 域内服务间,比如同时大麦电商之间的系统,最终目的是输出到日志。
面向外部传递
- 域内向域外
- 服务端传递到前端
- OpenAPI 错误码
- 内部不同域之间
错误码使用场景
- 通过错误码配置监控大盘。
- 通过日志进行问题排查,快速定位问题。
- 后端服务之间错误码传递。
- 前端展示的错误提示/OpenAPI。
本文希望从错误码使用的不同场景讨论得到一个合理的错误码规约,得到一个面向日志错误码标准和一个面向外部传递的错误码标准。
PS:本文引用全部引自阿里巴巴《Java 开发手册》,下称《手册》。
二 什么是错误码
错误码要回答的最根本的问题是,谁的错?错在哪?
那么一个错误能表示出谁的错和错在哪里就是一个好的错误码吗?答案显然是否定的,这个标准太基础了。
- 好的错误码必须能够快速知晓错误来源。
- 好的错误码必须易于记忆和对比。
- 好的错误码必须能够脱离文档和系统平台达到线下轻量沟通的目的(这个要求比较高)。
引自《手册》- 异常日志-错误码
错误码的制定原则:快速溯源、简单易记、沟通标准化。
说明:错误码想得过于完美和复杂,就像康熙字典中的生僻字一样,用词似乎精准,但是字典不容易随身携带并且简单易懂。
正例:错误码回答的问题是谁的错?错在哪?
1)错误码必须能够快速知晓错误来源,可快速判断是谁的问题。
2)错误码易于记忆和比对(代码中容易 equals)。
3)错误码能够脱离文档和系统平台达到线下轻量化地自由沟通的目的。
这个原则写在异常日志-错误码这个章节,我认为同样适用在面向用户的错误码。
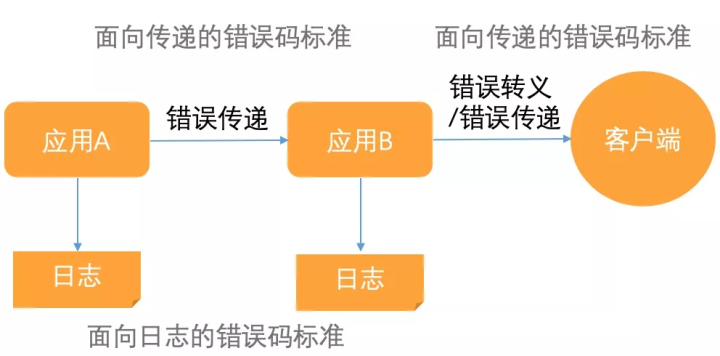
三 错误码规范
错误码定义要有字母也要有数字
纯数字错误码
错误码即人性,感性认知+口口相传,使用纯数字来进行错误码编排不利于感性记忆和分类。
说明:数字是一个整体,每位数字的地位和含义是相同的。
反例:一个五位数字 12345,第1位是错误等级,第 2 位是错误来源,345 是编号,人的大脑不会主动地分辨每位数字的不同含义。
《手册》说明了纯数字错误码存在的问题。
纯字母错误码
那么纯字母错误码不香吗?有两个问题:
- 对于使用汉语的我们用英语去准确描述一个错误有时是比较困难的。
- 纯英文字母的错误码不利于排序。
错误码尽量有利于不同文化背景的开发者进行交流与代码协作。
说明:英文单词形式的错误码不利于非英语母语国家(如阿拉伯语、希伯来语、俄罗斯语等)之间的开发者互相协作。
快速溯源 | 简单易记 | 沟通标准化
什么是快速溯源?就是一眼看上去就知道哪里出了什么问题。
李雷负责 A 服务,韩梅梅负责 B 服务。韩梅梅发现服务 B 出现了一个错误码,韩梅梅能够快速定位这是服务 A 的内部业务异常造成的问题,这个时候韩梅梅就可以拿着错误码找到李雷说,"hi,Li Lei,How old are you。(李雷,怎么老是你)"。李雷拿过来错误码一看,内心万马奔腾,一下就能知道这是上游 Polly 负责的应用阿尔法出了错。
怎么能达到这个效果呢?
- 首先要有一套标准并且在域内各个业务都在用同样的标准。
- 其次要求错误码有自我解释的能力是有信息含量的有意义。
- 最后在域内要传递错误码。
错误码标准的意义
开宗明义借用了《手册》对于错误码定义的原则作为错误码规范能够给我们带来的收益。我想再次强调并且试着从反面阐述没有错误码标准会带来的成本。
错误码是用来做沟通的:系统与系统间的沟通,人与人间的沟通,人与系统间的沟通。
试想下面这个场景:
韩梅梅看到一个异常日志其中一个纯数字的错误码。
韩梅梅需要理解这串数字代表的是什么,它到底是不是一个错误码,经过几秒钟确定下来这是一个错误码,但她不能确定这是不是本系统中错误码,因为在她负责的系统是由韩梅梅、Lucy 和 Lily 三个人共同维护的,每个人都按照自己的理解定义了一套错误码。
韩梅梅去系统源码中查找这个错误码,但是发现这个错误码并不是本系统的错误码。
然后再前翻两页后翻两页从日志上下文中确定这是李雷负责系统的错误码,“Li Lie,how old are you?”。
韩梅梅把错误码甩到李雷脸上,李雷一脸懵逼,这是我的系统的错误码吗?
李雷也不确定,因为李雷负责的系统是由李雷、林涛和 Jim 维护的,也是三人共同维护的。
李雷只好打开源码,还真是!
上边的场景经过了发现-初判断-判断来源-确定来源-沟通-二次判断-二次确认七个步骤。
希望上边的场景描述能够说明没有统一标准的错误所带来的成本。
四 面向日志的错误码
输出到日志的错误码有两个用途:
- 用来快速溯源找到问题。
- 用来形成监控大盘。
错误码设计
《手册》对于错误码的建议有非常多的可取参考的地方:
错误码不体现版本号和错误等级信息。
说明:错误码以不断追加的方式进行兼容。错误等级由日志和错误码本身的释义来决定。
错误码为字符串类型,共 5 位,分成两个部分:错误产生来源+四位数字编号。
错误码不能直接输出给用户作为提示信息使用。
说明:堆栈(stack_trace)、错误信息(error_message)、错误码(error_code)、提示信息(user_tip)是一个有效关联并互相转义的和谐整体,但是请勿互相越俎代庖。
在获取第三方服务错误码时,向上抛出允许本系统转义,由 C 转为 B,并且在错误信息上带上原有的第三方错误码。
结合错误码设计原则、错误码用途、规约建议,面向服务端日志的错误码应该是如下形式。
错误码分为一级宏观错误码、二级宏观错误码、三级宏观错误码。
错误码即人性,感性认知+口口相传,使用纯数字来进行错误码编排不利于感性记忆和分类。
说明:数字是一个整体,每位数字的地位和含义是相同的。
反例:一个五位数字 12345,第 1 位是错误等级,第 2 位是错误来源,345 是编号,人的大脑不会主动地分辨每位数字的不同含义。
按照《手册》的建议设计出的面向日志的错误码定义共十三位(十位有意义,三位连接符),并且应该具有如下分类:
- 应用标识,表示错误属于哪个应用,三位数字。
- 功能域标识,表示错误属于应用中的哪个功能模块,三位数字。
- 错误类型,表示错误属于那种类型,一位字母。
- 错误编码,错误类型下的具体错误,三位数字。
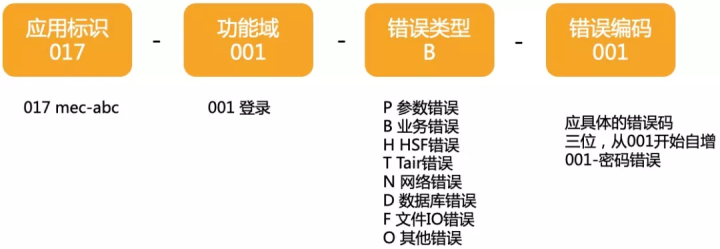
《手册》还有一条是规定错误码应该如何定义:
错误码为字符串类型,共 5 位,分成两个部分:错误产生来源+四位数字编号。
说明:错误产生来源分为 A/B/C,A 表示错误来源于用户,比如参数错误,用户安装版本过低,用户支付超时等问题;B 表示错误来源于当前系统,往往是业务逻辑出错,或程序健壮性差等问题;C 表示错误来源于第三方服务,比如 CDN 服务出错,消息投递超时等问题;四位数字编号从 0001 到 9999,大类之间的步长间距预留 100。
五位错误码的好处是易记,但是对于面向日志的错误码场景利用错误码制作需要分类的业务监控大盘将变得比较困难,比如统计应用 A 的功能 B 的错误出现次数。
同样在系统间传递这个类型的错误码非常有可能发生错误码冲突。
当然对于分为四段的错误码同样尤其不好的一面,应用标识和功能域标识需要有专人去管理或者开发一个错误码管理工具,否则时间一长很容易产生定义的混乱形成破窗。
《手册》对于错误码定义我认为非常适合面向外部传递的错误码。简单、易记、是大家熟悉的错误码样式,并且透出的错误码数量是非常有限的。
不用枚举定义错误码
国际化支持是一个不使用枚举定义错误码很重要的理由。
我们通过 i18n 的支持可以做到错误码、错误状态、错误描述的管理。
五 面向外部传递的错误码
面向外部传递的错误码是为了把域内的错误信息传递出去。
可以让域外系统通过错误码进行错误码进行后续的动作或是中断操作或是记录日志继续执行。
可以让前端通过错误码给出用户准确的错误提示或者忽略错误进行重试。
错误码设计
根据《手册》给出的错误码定义建议设计出的面向外部传递的错误码共五位,并且有如下分类:
- 错误类型,表示错误来源,一位字母。
- 错误编码,表示具体错误,四位数字。

本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java