
Flink 在快手实时多维分析场景的应用
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
Flink 在快手应用场景及规模
首先看 Flink 在快手的应用场景和规模。
1. 快手应用场景
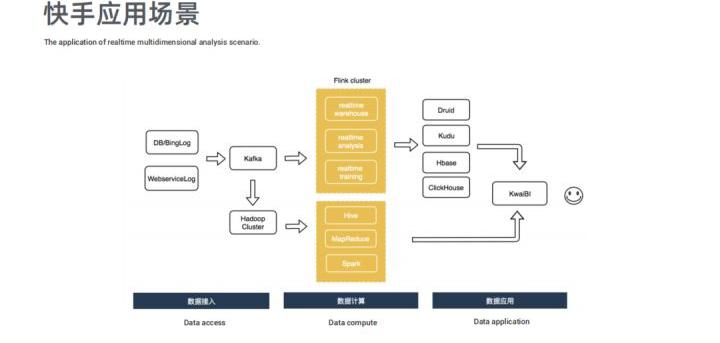
快手计算链路是从 DB/Binlog 以及 WebService Log 实时入到 Kafka 中,然后接入 Flink 做实时计算,其中包括实时数仓、实时分析以及实时训练,最后的结果存到 Druid、Kudu、HBase 或者 ClickHouse 里面;同时 Kafka 数据实时 Dump 一份到 Hadoop 集群,然后通过 Hive、MapReduce 或者 Spark 来做离线计算;最终实时计算和离线计算的结果数据会用内部自研 BI 工具 KwaiBI 来展现出来。

Flink 在快手典型的应用场景主要分为三大类:
- 80% 统计监控:实时统计,包括各项数据的指标,监控项报警,用于辅助业务进行实时分析和监控;
- 15% 数据处理:对数据的清洗、拆分、Join 等逻辑处理,例如大 Topic 的数据拆分、清洗;
- 5% 数据处理:实时业务处理,针对特定业务逻辑的实时处理,例如实时调度。

Flink 在快手应用的典型场景案例包括:
- 快手是分享短视频跟直播的平台,快手短视频、直播的质量监控是通过 Flink 进行实时统计,比如直播观众端、主播端的播放量、卡顿率、开播失败率等跟直播质量相关的多种监控指标;
- 用户增长分析,实时统计各投放渠道拉新情况,根据效果实时调整各渠道的投放量;
- 实时数据处理,广告展现流、点击流实时 Join,客户端日志的拆分等;
- 直播 CDN 调度,实时监控各 CDN 厂商质量,通过 Flink 实时训练调整各个 CDN 厂商流量配比。
2. Flink 集群规模

快手目前集群规模有 1500 台左右,日处理条目数总共有3万亿,峰值处理条目数大约是 3亿/s 左右。集群部署都是 On Yarn 模式,实时集群和离线集群混合部署,通过 Yarn 标签进行物理隔离,实时集群是 Flink 专用集群,针对隔离性、稳定性要求极高的业务部署。注:本文所涉及数据仅代表嘉宾分享时的数据。
快手实时多维分析平台
此处重点和大家分享下快手的实时多维分析平台。
1. 快手实时多维分析场景

快手内部有这样的应用场景,每天的数据量在百亿级别,业务方需要在数据中任选五个以内的维度组合进行全维的建模进而计算累计的 PV ( Page View 访问量 )、UV ( Unique Visitor 独立访客 )、新增或者留存等这样的指标,然后指标的计算结果要实时进行图形化报表展示供给业务分析人员进行分析。
2. 方案选型
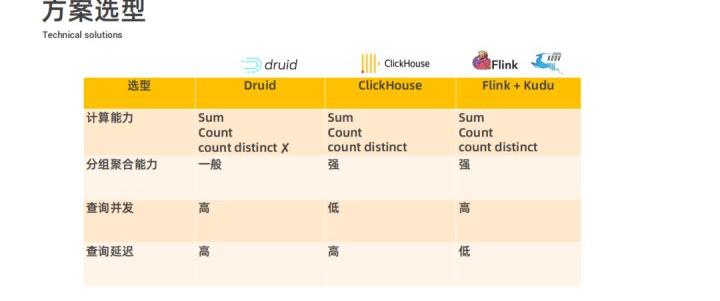
现在社区已经有一些 OLAP 实时分析的工具,像 Druid 和 ClickHouse;目前快手采用的是 Flink+Kudu 的方案,在前期调研阶段对这三种方案从计算能力、分组聚合能力、查询并发以及查询延迟四个方面结合实时多维查询业务场景进行对比分析:
- 计算能力方面:多维查询这种业务场景需要支持 Sum、Count 和 count distinct 等能力,而 Druid 社区版本不支持 count distinct,快手内部版本支持数值类型、但不支持字符类型的 count distinct;ClickHouse 本身全都支持这些计算能力;Flink 是一个实时计算引擎,这些能力也都具备。
- 分组聚合能力方面:Druid 的分组聚合能力一般,ClickHouse 和 Flink 都支持较强的分组聚合能力。
- 查询并发方面:ClickHouse 的索引比较弱,不能支持较高的查询并发,Druid 和 Flink 都支持较高的并发度,存储系统 Kudu,它也支持强索引以及很高的并发。
- 查询延迟方面:Druid 和 ClickHouse 都是在查询时进行现计算,而 Flink+Kudu 方案,通过 Flink 实时计算后将指标结果直接存储到 Kudu 中,查询直接从 Kudu 中查询结果而不需要进行计算,所以查询延迟比较低。
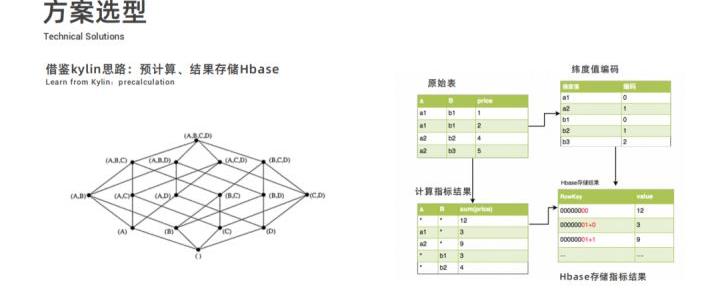
采用 Flink+Kudu 的方案主要思想是借鉴了 Kylin 的思路,Kylin 可以指定很多维度和指标进行离线的预计算然后将预计算结果存储到 Hbase 中;快手的方案是通过 Flink 实时计算指标,再实时地写到 Kudu 里面。
3. 方案设计
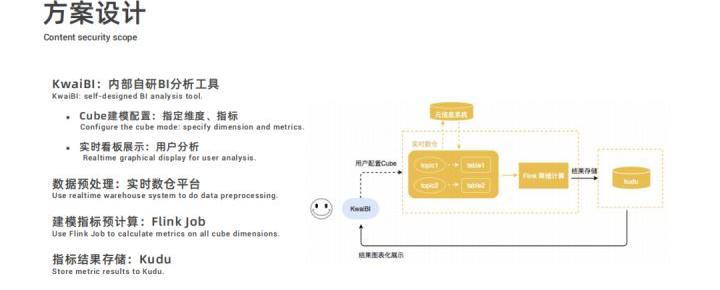
实时多维分析的整体的流程为:
- 用户在快手自研的 BI 分析工具 KwaiBI 上配置 Cube 数据立方体模型,指定维度列和指标列以及基于指标做什么样的计算;
- 配置过程中选择的数据表是经过处理过后存储在实时数仓平台中的数据表;
- 然后根据配置的计算规则通过 Flink 任务进行建模指标的预计算,结果存储到 Kudu 中;
- 最后 KwaiBI 从 Kudu 中查询数据进行实时看板展示。
接下来详细介绍一下实时多维分析的主要模块。
■ 数据预处理
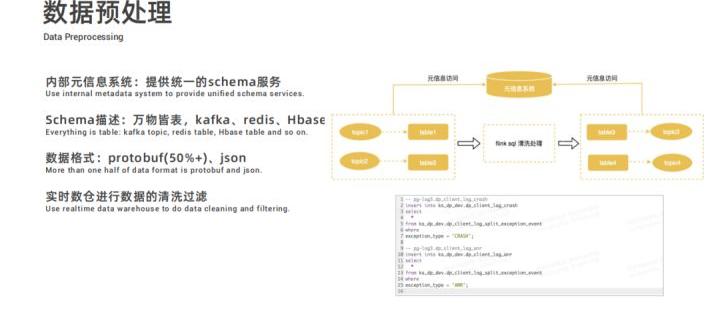
KwaiBI 配置维度建模时选择的数据表,是经过提前预处理的:
- 首先内部有一个元信息系统,在元信息系统中提供统一的 schema 服务,所有的信息都被抽象为逻辑表;
- 例如 Kafka 的 topic、Redis、Hbase 表等元数据信息都抽取成 schema 存储起来;
- 快手 Kafka 的物理数据格式大部分是 Protobuf 和 Json 格式,schema 服务平台也支持将其映射为逻辑表;
- 用户只需要将逻辑表建好之后,就可以在实时数仓对数据进行清洗和过滤。
■ 建模计算指标
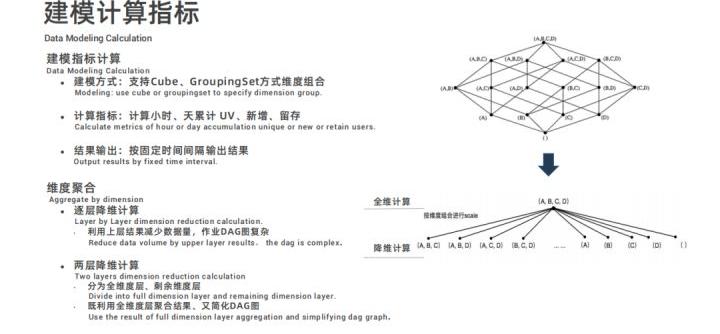
数据预处理完成后,最重要的步骤是进行建模指标计算,此处支持 Cube、GroupingSet 方式维度组合来计算小时或者天累计的 UV ( Unique Visitor )、新增和留存等指标,可以根据用户配置按固定时间间隔定期输出结果;维度聚合逻辑中,通过逐层降维计算的方式会让 DAG 作业图十分复杂,如上图右上角模型所示;因此快手设计了两层降维计算模型,分为全维度层和剩余维度层,这样既利用了全维度层的聚合结果又简化了 DAG 作业图。
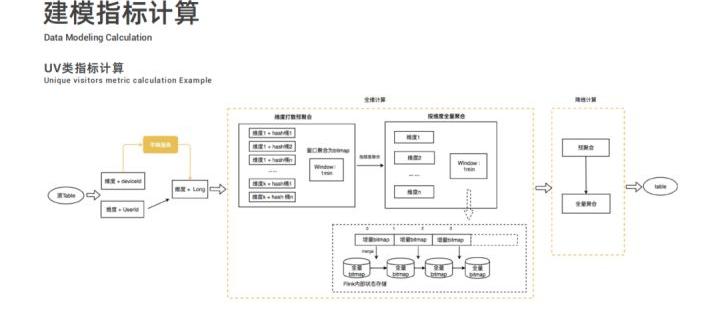
以 UV 类指标计算举例,两个黄色虚线框分别对应两层计算模块:全维计算和降维计算。
- 全维计算分为两个步骤,为避免数据倾斜问题,首先是维度打散预聚合,将相同的维度值先哈希打散一下。因为 UV 指标需要做到精确去重,所以采用 Bitmap 进行去重操作,每分钟一个窗口计算出增量窗口内数据的 Bitmap 发送给第二步按维度全量聚合;在全量聚合中,将增量的 Bitmap 合并到全量 Bitmap 中最终得出准确的 UV 值。然而有人会有问题,针对用户 id 这种的数值类型的可以采用此种方案,但是对于 deviceid 这种字符类型的数据应该如何处理?实际上在源头,数据进行维度聚合之前,会通过字典服务将字符类型的变量转换为唯一的 Long 类型值,进而通过 Bitmap 进行去重计算 UV。
- 降维计算中,通过全维计算得出的结果进行预聚合然后进行全量聚合,最终将结果进行输出。
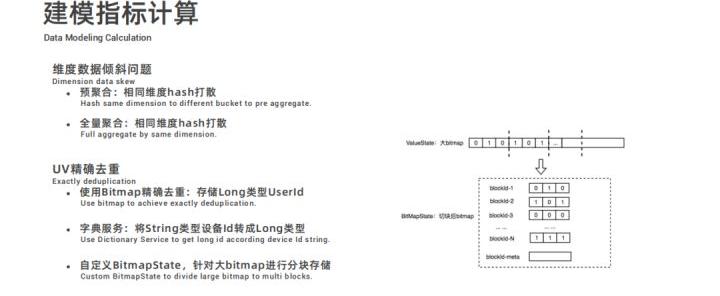
再重点介绍下,建模指标计算中的几个关键点。在建模指标计算中,为了避免维度数据倾斜问题,通过预聚合 ( 相同维度 hash 打散 ) 和全量聚合 ( 相同维度打散后聚合 ) 两种方式来解决。
为了解决 UV 精确去重问题,前文有提到,使用 Bitmap 进行精确去重,通过字典服务将 String 类型数据转换成 Long 类型数据进而便于存储到 Bitmap 中,因为统计 UV 要统计历史的数据,比如说按天累计,随着时间的推移,Bitmap 会越来越大,在 Rocksdb 状态存储下,读写过大的 KV 会比较耗性能,所以内部自定义了一个 BitmapState,将 Bitmap 进行分块存储,一个 blockid 对应一个局部的 bitmap,这样在 RocksDB 中存储时,一个 KV 会比较小,更新的时候也只需要根据 blockid 更新局部的 bitmap 就可以而不需要全量更新。
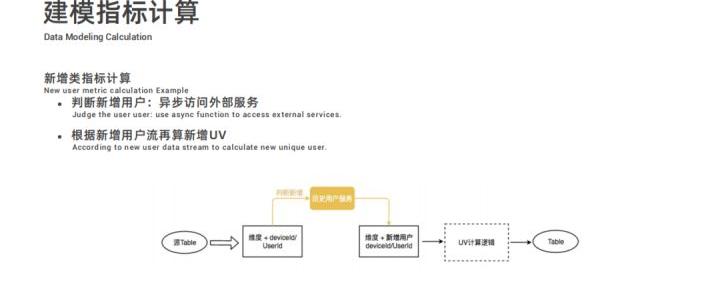
接下来,看新增类的指标计算,和刚刚 UV 的不同点是需要判断是否为新增用户,通过异步地访问外部的历史用户服务进行新增用户判断,再根据新增用户流计算新增 UV,这块计算逻辑和 UV 计算一致。
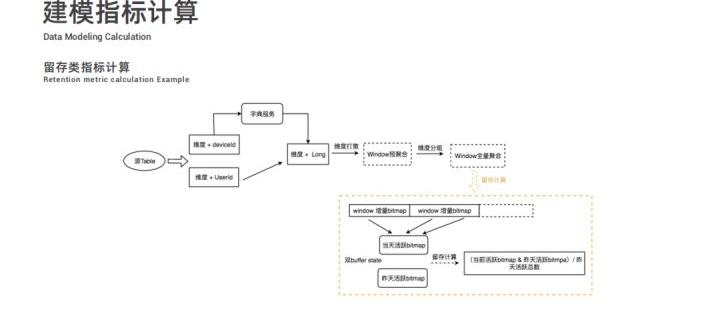
然后,再来看留存类指标计算,与 UV 计算不同的时候,不仅需要当天的数据还需要前一天的历史数据,这样才能计算出留存率,内部实现的时候是采用双 buffer state 存储,在计算的时候将双 buffer 数据相除就可以计算出留存率。
■ Kudu 存储

最后经过上面的计算逻辑后,会将结果存储到 Kudu 里面,其本身具有低延迟随机读写以及快速列扫描等特点,很适合实时交互分析场景;在存储方式上,首先对维度进行编码,然后按时间+维度组合+维度值组合作为主键,最终按维度组合、维度值组合、时间进行分区,这样有利于提高查询的效率快速获取到数据。
4. KwaiBI 展示
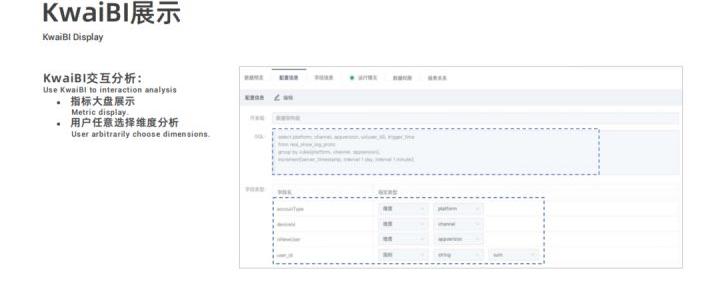
界面为配置 Cube 模型的截图,配置一些列并指定类型,再通过一个 SQL 语句来描述指标计算的逻辑,最终结果也会通过 KwaiBI 展示出来。
SlimBase-更省 IO、嵌入式共享 state 存储
接下来介绍一种比 RocksDB 更省 IO、嵌入式的共享 state 存储引擎:SlimBase。
1. 面临的挑战
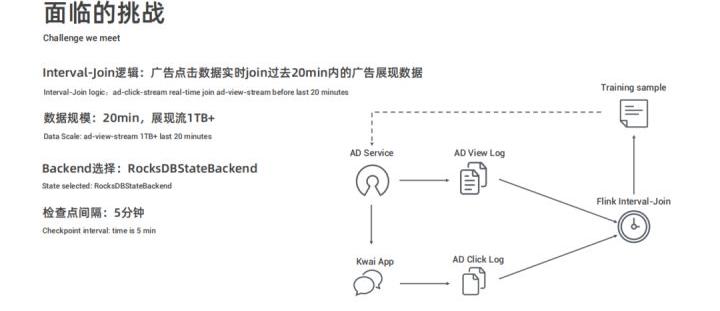
首先看一下 Flink 使用 RocksDB 遇到的问题,先阐述一下快手的应用场景、广告展现点击流实时 Join 场景:打开快手 App 可能会收到广告服务推荐的广告视频,用户可能会点击展现的广告视频。
这样的行为在后端会形成两份数据流,一份是广告展现日志,一份是客户端点击日志。这两份数据进行实时 Join,并将 Join 结果作为样本数据用于模型训练,训练出的模型会被推送到线上的广告服务。
该场景下展现以后20分钟的点击被认为是有效点击,实时 Join 逻辑则是点击数据 Join 过去20分钟内的展现。其中,展现流的数据量相对比较大,20分钟数据在 1TB 以上。检查点设置为五分钟,Backend 选择 RocksDB。

在这样的场景下,面临着磁盘 IO 开销70%,其中50%开销来自于 Compaction;在 Checkpoint 期间,磁盘 IO 开销达到了100%,耗时在1~5分钟,甚至会长于 Checkpoint 间隔,业务能明显感觉到反压。经过分析找出问题:
- 首先,在 Checkpoint 期间会产生四倍的大规模数据拷贝,即:从 RocksDB 中全量读取出来然后以三副本形式写入到 HDFS 中;
- 其次,对于大规模数据写入,RocksDB 的默认 Level Compaction 会有严重的 IO 放大开销。
2. 解决方案

由于出现上文阐述的问题,开始寻找解决方案,整体思路是在数据写入时直接落地到共享存储中,避免 Checkpoint 带来的数据拷贝问题。手段是尝试使用更省 IO 的 Compaction,例如使用 SizeTieredCompation 方式,或者利用时序数据的特点使用并改造 FIFOCompaction。综合比较共享存储、SizeTieredCompation、基于事件时间的 FIFOCompaction 以及技术栈四个方面得出共识:HBase 代替 RocksDB 方案。
- 共享存储方面,HBase 支持, RocksDB 不支持
- SizeTieredCompation 方面,RocksDB 默认不支持,HBase 默认支持
- 基于事件时间下推的 FIFOCompaction 方面,RocksDB 不支持,但 HBase 开发起来比较简单
- 技术栈方面,RocksDB 使用 C++,HBase 使用 java,HBase 改造起来更方便

但是 HBase 有些方面相比 RocksDB 较差:
- HBase 是一个依赖 zookeeper、包含 Master 和 RegionServer 的重量级分布式系统;而 RocksDB 仅是一个嵌入式的 Lib 库,很轻量级。
- 在资源隔离方面,HBase 比较困难,内存和 cpu 被多个 Container 共享;而 RocksDB 比较容易,内存和 cpu 伴随 Container 天生隔离。
- 网络开销方面,因为 HBase 是分布式的,所有比嵌入式的 RocksDB 开销要大很多。
综合上面几点原因,快手达成了第二个共识,将 HBase 瘦身,改造为嵌入式共享存储系统。
3. 实现方案
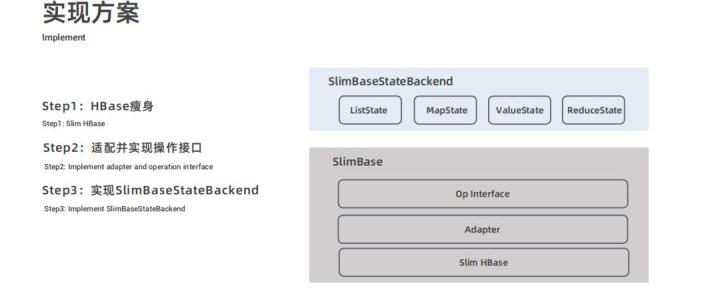
接下来介绍一下将 HBase 改造成 SlimBase 的实现方案,主要是分为两层:
- 一层是 SlimBase 本身,包含三层结构:Slim HBase、适配器以及接口层;
- 另一层是 SlimBaseStateBackend,主要包含 ListState、MapState、ValueState 和 ReduceState。
后面将从 HBase 瘦身、适配并实现操作接口以及实现 SlimBaseStateBackend 三个步骤分别进行详细介绍。
■ HBase 瘦身

先讲 HBase 瘦身,主要从减肥和增瘦两个步骤,在减肥方面:
- 先对 HBase 进行减裁,去除 client、zookeeper 和 master,仅保留 RegionServer
- 再对 RegionServer 进行剪裁,去除 ZK Listener、Master Tracker、Rpc、WAL 和 MetaTable
- 仅保留 RegionServer 中的 Cache、Memstore、Compaction、Fluster 和 Fs
在增瘦方面:
- 将原来 Master 上用于清理 Hfile 的 HFileCleaner 迁移到 RegionServer 上
- RocksDB 支持读放大写的 merge 接口,但是 SlimBase 是不支持的,所以要实现 merge 的接口
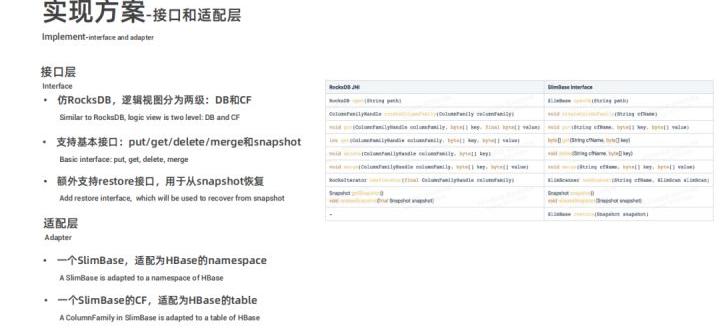
接口层主要有以下三点实现:
- 仿照 RocksDB,逻辑视图分为两级:DB 和 ColumnFamily
- 支持一些基本的接口:put/get/delete/merge 和 snapshot
- 额外支持了 restore 接口,用于从 snapshot 中恢复
适配层主要有以下两个概念:
- 一个 SlimBase 适配为 Hbase 的 namespace
- 一个 SlimBase 的 ColumnFamily 适配为 HBase 的 table
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java