
实例讲解常用SQL语句的各种查询案例,包括分组统计、最小最大函数等。
说明:以下SQL语句都用下表进行说明的,使用时请根据自己的表名和字段名进行修改匹配。
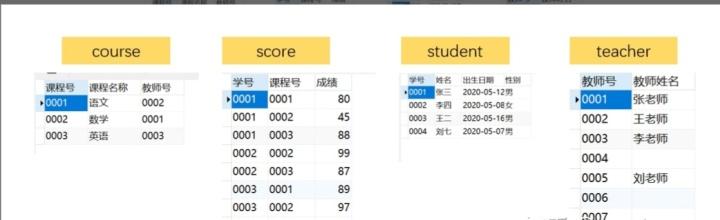
一.简单查询
模糊查询,查询教师表信息:使用like '%字符串%'等语句来进行查询。
-- 查询姓张的老师名单
SELECT *
FROM teacher
where `教师姓名`LIKE '张%'
-- 查询名字中最后两个字带有‘老师’的老师名单
SELECT *
FROM teacher
where `教师姓名`LIKE '%老师'
-- 查询名字中带有‘老师’二字的老师名单
SELECT *
FROM teacher
where `教师姓名`LIKE '%老师%'
-- 查询姓张的老师个数
SELECT count('教师姓名')
FROM teacher
where `教师姓名`LIKE '张%'二.汇总分析
也就是使用count,sum,max,min等语句来查询
--查询课程编号为'0002'的总成绩
/*查询思路:
SELECT查询结果[SUM成绩]
FROM 查询表[course]
WHERE筛选条件 '课程号'=‘0002’*/
select SUM(`成绩`) as 总成绩
from score
where `课程号`=0002;--查询选了该课程的学生数
/*查询思路:
SELECT查询结果[COUNT(DISTINCT `学号`)]
FROM 查询表[course]
WHERE筛选条件 无*/
select COUNT(DISTINCT `学号`) as 选课人数
from score;--查询选了该课程的最高和最低成绩
/*查询思路:
SELECT 查询结果[课程号,MAX(成绩),MIN(成绩)]
FROM 查询地址[score]
WHERE 筛选条件[]
GROUP BY 分组[课程号]
HAVING 对分组结果指定条件[无]*/
select `课程号`,MAX(`成绩`) as 最高成绩,MIN(`成绩`) as 最低成绩
from score
group by `课程号`;--查询至少选修两门课程的学生学号
/*
——题目:查询至少选修两门课程的学生学号
【翻译】
1)先计算出每个学生选修的课程数据,按学号分组
2)至少选修两门课程:学生选修课程数量>=2,对分组结果指定条件
【查询思路】
SELECT 查询结果[学号,每个学生选修课程数目:汇总函数count]
FROM 查询地址[课程表score]
WHERE 筛选条件[至少选修两门课程:需要先极端出每个学生选修了多少门课程,需要用到分组故这里没有子句]
GROUP BY 分组[按学号分组]
HAVING 对分组结果指定条件[每个学生选修课程数目>=2]*/
select `学号`,COUNT(`课程号`) as 选修课程数目
from score
group by `学号`
HAVING count(学号)>=2--查询同名同姓学生名单并统计同名人数
/*
——题目:查询同名同姓学生名单并统计同名人数
【翻译】
1)先按姓名分组筛选出名字出现次数
2)然后通过条件筛选出名字出现>=2次的
【查询思路】
SELECT 查询结果[姓名,count姓名出现次数]
FROM 查询地址[学生表student]
WHERE 筛选条件[无]
GROUP BY 分组[按姓名分组]
HAVING 对分组结果指定条件[学生姓名出现次数>=2]*/
select `姓名`,COUNT(`姓名`) as 重复次数
from student
group by `姓名`
HAVING count(`姓名`)>=2--查询每门课程的平均成绩,结果按平均成绩升序,课程号降序排列
select 课程号,avg(成绩)as 平均成绩
from score
group by 课程号
order by 平均成绩 asc,课程号desc;--查询两门以上不及格课程的学号,以及不及格课程的平均成绩
select 学号,avg(成绩)as 平均成绩
from score
where 成绩=2三.复杂查询
--查询所有课程成绩小于60分学生的学号、姓名
/*
——题目:查询所有成绩小于60分学生的学号,姓名
【查询思路】
SELECT 查询结果[学号,姓名,成绩]
FROM 查询地址[学生表student,成绩表score]
WHERE 筛选条件[成绩<60]
GROUP BY 分组[无]
HAVING 对分组结果指定条件[无]*/
select a.`学号`,a.`姓名`,b.`成绩`
from student as a LEFT JOIN score as b
ON a.`学号`=b.`学号`
WHERE b.`成绩`<60;--查询没有学全所有课的学生的学号、姓名
/*
——题目:查询,没有学全所有课的学生的学号,姓名
【查询思路】
SELECT 查询结果[学号,姓名]
FROM 查询地址[学生表student]
WHERE 筛选条件[用in子查询对比学习课程总数比课程表中课程总数少的学生]
GROUP BY 分组[无]
HAVING 对分组结果指定条件[无]*/
select `学号`,`姓名`
FROM student
WHERE `学号` in(
SELECT `学号`
FROM score
GROUP BY `学号`
HAVING COUNT(课程号)<(SELECT COUNT(课程号) FROM course));--查询出只选修了两门课程的全部学生的学号和姓名
/*
——题目:查询出只选修了两门课程的全部学生的学号和姓名
【查询思路】
SELECT 查询结果[学号,姓名]
FROM 查询地址[学生表student]
WHERE 筛选条件[用in子查询+count函数统计课程表中学习课程为2门的学生]
GROUP BY 分组[无]
HAVING 对分组结果指定条件[无]*/
select `学号`,`姓名`
FROM student
WHERE `学号` in(
SELECT `学号`
FROM score
GROUP BY `学号`
HAVING COUNT(课程号)=2);--查询出1990年出生的学生名单
日期函数:
current_date
current_time
current_stamp
year/month/day
dayname: 获取日期是星期几
Select 学号,姓名
from student
where year(’出生日期‘)=1990;四.分组取最大值,最小值,每组最大的N条记录(TOP N问题)
--查询各科成绩的前2名的记录
/*
——题目:查询各科成绩的前2名的记录
(select *
from score
where 课程号 = ’0001‘
order by 成绩 desc
limit 2)
union all
(select *
from score
where 课程号 = ’0002‘
order by 成绩 desc
limit 2)
union all
(select *
from score
where 课程号 = ’0003‘
order by 成绩 desc
limit 2)主要是使用order by语句进行排序,然后再使用limit来获取前几列的数据
五.多表查询
--查询没有选择课程的同学的学号,姓名
/*
——题目:查询没有选择课程的同学的学号,姓名
【翻译】
找出在学生表中,但是不在课程表中的学生
/*查询思路:
SELECT 查询结果[学号,姓名]
FROM 查询地址[学生表student,课程表score,左联结]
ON 联结主键[学号]
WHERE 筛选条件[课程号为null的学生]
GROUP BY 分组[课程号]
HAVING 对分组结果指定条件[无]
ORDER BY 对数据排序[无]
LIMIT 从查询结果抽取展示的行[无]*/
select a.`学号`,a.`姓名`
FROM student as a LEFT JOIN score as b
ON a.`学号`=b.`学号`
WHERE b.`课程号` is Null;--行列转换
第一步 使用常量列输出同目表的结构
select 学号,'课程号0001',,'课程号0002',,'课程号0003'
from score;
第二步 使用case 表达式
select 学号,
((case 课程号 when ’0001‘ then 成绩 else 0 end) as ’课程号0001 ‘),
((case 课程号 when ’0002‘ then 成绩 else 0 end) as ’课程号0002 ‘),((case 课程号 when ’0003‘ then 成绩 else 0 end) as ’课程号0003 ‘)
from score
第三步 分组
select 学号,
max ((case 课程号 when ’0001‘ then 成绩 else 0 end) as ’课程号0001 ‘),
max ((case 课程号 when ’0002‘ then 成绩 else 0 end) as ’课程号0002 ‘),max ((case 课程号 when ’0003‘ then 成绩 else 0 end) as ’课程号0003 ‘)
from score
group by 学号六.如何提高SQL查询效率
6.1. select子句中尽量避免使用*
select子句中,*是选择全部数据的意思。比如语句:“select * from 成绩表”,意思是选择成绩表中所有列的数据。
在我们平时的练习中,往往没有那么多数据,所以很多同学会图方便使用*。而在处理公司事务时,动辄十万、百万,甚至上千万的数据,这个时候再用*,那么接下来的几分钟就只能看着电脑屏幕发呆了。
所以,在我们平常的练习中,就要养成好的习惯,最后需要哪些列的数据,就提取哪些列的数据。尽量少用*来获取数据。
另外,如果select * 用于多表联结,会造成更大的成本开销。
6.2. where子句比较符号左侧避免函数
尽量避免在where条件子句中,比较符号的左侧出现表达式、函数等操作。因为这会导致数据库引擎进行全表扫描,从而增加运行时间。
按照题目的思路直接书写,“给每人加5分后,成绩90分以上”的条件很多人会这样写:
where 成绩 + 5 › 90 (表达式在比较符号的左侧)优化方法:
where 成绩 › 90 – 5(表达式在比较符号的右侧)所以,为了提高效率,where子句中遇到函数或加减乘除的运算,应当将其移到比较符号的右侧。
6.3. 尽量避免使用in和not in
in和not in也会导致数据库进行全表搜索,增加运行时间。
比如,我想看看第8、9个人的学号和成绩,大多数同学会用这个语句:
select 学号, 成绩
from 成绩表
where 学号 in (8, 9)这一类语句,优化方法如下:
select 学号, 成绩
from 成绩表
where 学号 between 8 and 96.4. 尽量避免使用or
or同样会导致数据库进项全表搜索。在工作中,如果你只想用or从几十万语句中取几条出来,是非常划不来的,怎么办呢?下面的方法可替代or。
从成绩表中选出成绩是是88分或89分学生的学号:
select 学号
from 成绩表
where 成绩 = 88 or 成绩 = 89优化后:
select 学号 from 成绩表 where 成绩 = 88
union
select 学号 from 成绩表 where 成绩 = 89语句虽然变长了一点,但处理大量数据时,可以省下很多时间,是非常值得的。
6.5.使用limit子句限制返回的数据行数
如果前台只需要显示15行数据,而你的查询结果集返回了1万行,那么这适合最好使用limt子句来限制查询返回的数据行数。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java