
什么是 Git LFS和应用?
Git 是分布式 版本控制系统,这意味着在克隆过程中会将仓库的整个历史记录传输到客户端。对于包涵大文件(尤其是经常被修改的大文件)的项目,初始克隆需要大量时间,因为客户端会下载每个文件的每个版本。Git LFS(Large File Storage)是由 Atlassian, GitHub 以及其他开源贡献者开发的 Git 扩展,它通过延迟地(lazily)下载大文件的相关版本来减少大文件在仓库中的影响,具体来说,大文件是在 checkout 的过程中下载的,而不是 clone 或 fetch 过程中下载的(这意味着你在后台定时 fetch 远端仓库内容到本地时,并不会下载大文件内容,而是在你 checkout 到工作区的时候才会真正去下载大文件的内容)。
Git LFS 通过将仓库中的大文件替换为微小的指针(pointer) 文件来做到这一点。在正常使用期间,你将永远不会看到这些指针文件,因为它们是由 Git LFS 自动处理的:
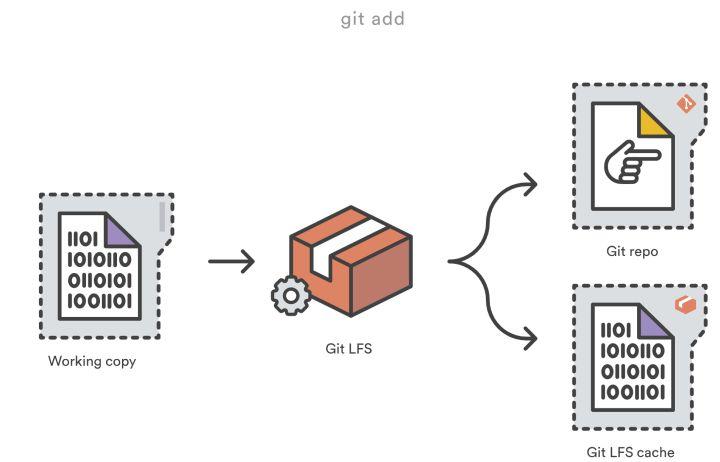
\1. 当你添加(执行 git add 命令)一个文件到你的仓库时,Git LFS 用一个指针替换其内容,并将文件内容存储在本地 Git LFS 缓存中(本地 Git LFS 缓存位于仓库的.git/lfs/objects 目录中)。
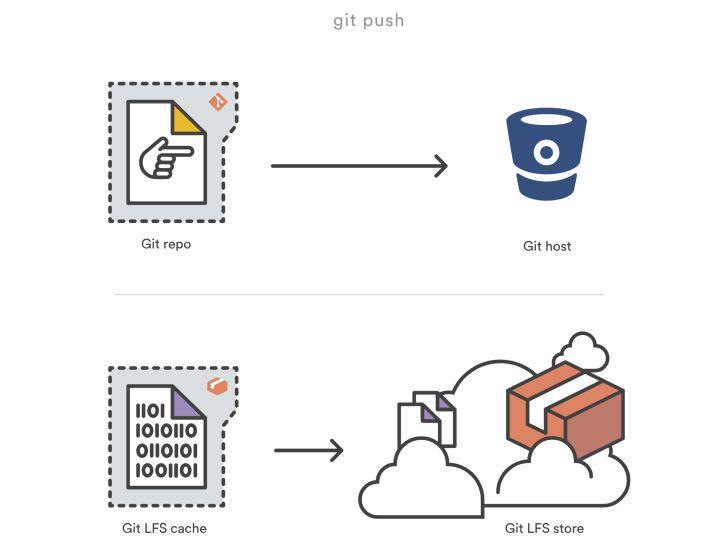
\2. 当你推送新的提交到服务器时,新推送的提交引用的所有 Git LFS 文件都会从本地 Git LFS 缓存传输到绑定到 Git 仓库的远程 Git LFS 存储(即 LFS 文件内容会直接从本地 Git LFS 缓存传输到远程 Git LFS 存储服务器)。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java