
如何更高效地压缩时序数据?基于深度强化学习的探索。
深度学习的本质是做决策,用它解决具体的问题时很重要的是找到契合点,合理建模,然后整理数据优化 loss 等最终较好地解决问题。在过去的一段时间,我们在用深度强化学习进行数据压缩上做了一些研究探索并取得了一些成绩,已经在 ICDE 2020 research track 发表(Two-level Data Compression using Machine Learning in Time Series Database)并做了口头汇报。在这里做一个整体粗略介绍,希望对其它的场景,至少是其它数据的压缩等,带来一点借鉴作用。
背景描述
1 时序数据
时序数据顾名思义指的是和时间序列相关的数据,是日常随处可见的一种数据形式。下图罗列了三个示例:a)心电图,b)股票指数,c)具体股票交易数据。
关于时序数据库的工作内容,简略地,在用户的使用层面它需要响应海量的查询,分析,预测等;而在底层它则需要处理海量的读写,压缩解压缩,采用聚合等操作,而这些的基本操作单元就是时序数据 ,一般(也可以简化)用两个 8 byte 的值进行统一描述。
可以想象,任何电子设备每天都在产生各种各样海量的时序数据,需要海量的存储空间等,对它进行压缩存储及处理是一个自然而然的方法。而这里的着重点就是如何进行更高效的压缩。
2 强化学习
机器学习按照样本是否有 groundTruth 可分为有监督学习,无监督学习,以及强化学习等。强化学习顾名思义是不停地努力地去学习,不需要 groundTruth,真实世界很多时候也没有 groundTruth,譬如人的认知很多时候就是不断迭代学习的过程。从这个意义上来说,强化学习是更符合或更全面普遍的一种处理现实世界问题的过程和方法,所以有个说法是:如果深度学习慢慢地会像 C/Python/Java 那样成为解决具体问题的一个基础工具的话,那么强化学习是深度学习的一个基础工具。
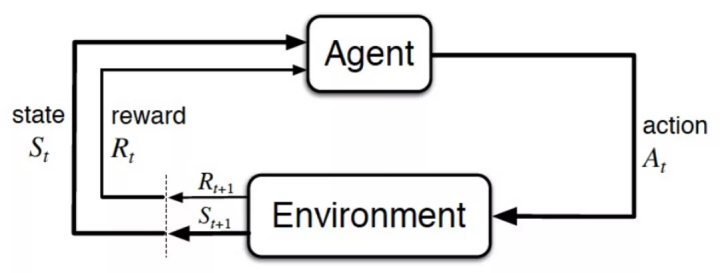
强化学习的经典示意图如下,基本要素为 State,Action,和 Environment。基本过程为:Environment 给出 State,Agent 根据 state 做 Action 决策,Action 作用在 Environment 上产生新的 State 及 reward,其中 reward 用来指导 Agent 做出更好的 Action 决策,循环往复….
而常见的有监督学习则简单很多,可以认为是强化学习的一种特殊情况,目标很清晰就是 groudTruth,因此对应的 reward 也比较清晰。
强化学习按照个人理解可以归纳为以下三大类:
1)DQN
Deep Q network,比较符合人的直观感受逻辑的一种类型,它会训练一个评估 Q-value 的网络,对任一 state 能给出各个 Action 的 reward,然后最终选择 reward 最大的那个 action 进行操作即可。训练过程通过评估 “估计的 Q-value” 和 “真正得到的 Q-value” 的结果进行反向传递,最终让网络估计 Q-value 越来越准。
2)Policy Gradient
是更加端到端的一种类型,训练一个网络,对任一 state 直接给出最终的 action。DQN 的适用范围需要连续 state 的 Q-value 也比较连续(下围棋等不适用这种情况),而 Policy Gradient 由于忽略内部过程直接给出 action,具有更大的普适性。但它的缺点是更难以评价及收敛。一般的训练过程是:对某一 state,同时随机的采取多种 action,评价各种 action 的结果进行反向传递,最终让网络输出效果更好的 action。
3)Actor-Critic
试着糅合前面两种网络,取长补短,一方面用 policy Gradient 网络进行任一 state 的 action 输出,另外一方面用 DQN 网络对 policy gradient 的 action 输出进行较好的量化评价并以之来指导 policy gradient 的更新。如名字所示,就像表演者和评论家的关系。训练过程需要同时训练 actor(policy Graident)和 critic(QN)网络,但 actor 的训练只需要 follow critic 的指引就好。它有很多的变种,也是当前 DRL 理论研究上不停发展的主要方向。
时序数据的压缩
对海量的时序数据进行压缩是显而易见的一个事情,因此在学术界和工业界也有很多的研究和探索,一些方法有:
- Snappy:对整数或字符串进行压缩,主要用了长距离预测和游程编码(RLE),广泛的应用包括 Infuxdb。
- Simple8b:先对数据进行前后 delta 处理,如果相同用RLE编码;否则根据一张有 16 个 entry 的码表把 1 到 240 个数(每个数的 bits 根据码表)pack 到 8B 为单位的数据中,有广泛的应用包括 Infuxdb。
- Compression planner:引入了一些 general 的压缩 tool 如 scale, delta, dictionary, huffman, run length 和 patched constant 等,然后提出了用静态的或动态办法组合尝试这些工具来进行压缩;想法挺新颖但实际性能会是个问题。
- ModelarDB:侧重在有损压缩,基于用户给定的可容忍损失进行压缩。基本思想是把维护一个小 buff,探测单前数据是否符合某种模式(斜率的直线拟合),如果不成功,切换模式重新开始buff等;对支持有损的 IoT 领域比较合适。
- Sprintz:也是在 IoT 领域效果会比较好,侧重在 8/16 bit 的整数处理;主要用了 scale 进行预测然后用 RLC 进行差值编码并做 bit-level 的 packing。
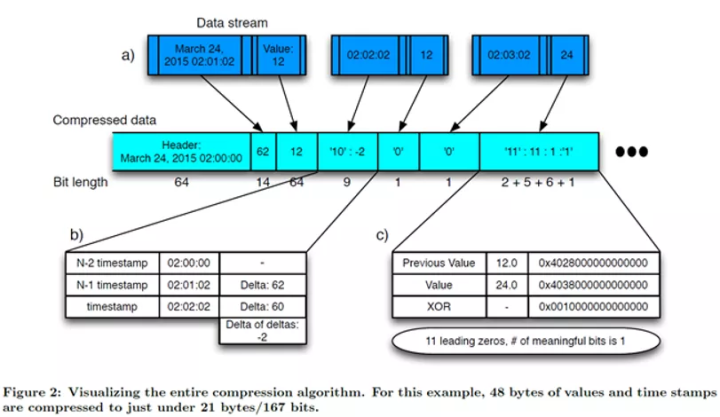
- Gorilla:应用在 Facebook 高吞吐实时系统中的当时 sofa 的压缩算法,进行无损压缩,广泛适用于 IoT 和云端服务等各个领域。它引入 delta-of-delta 对时间戳进行处理,用 xor 对数据进行变换然后用 Huffman 编码及 bit-packing。示例图如下所示。
- MO:类似 Gorilla,但去掉了 bit-packing,所有的数据操作基本都是字节对齐,降低了压缩率但提供了处理性能。
- …
还有很多相关的压缩算法,总的来说:
- 它们基本都是支持单模式,或者有限的偏static的模式进行数据的压缩。
- 很多为了提高压缩率,都用了 bit-packing (甚至有损压缩),但对越来越广泛使用的并行计算不太友好。
两阶段的基于深度学习的压缩算法
1 时序数据压缩的特性
时序数据来源于 IoT、金融、互联网、业务管理监控等方方面面,形态特性相差很多,然后对数据精确度等的要求也不尽相同。如果只能有一种统一的压缩算法进行无差别对待地处理,那应该是基于无损的、用 8B 数据进行数据描述的算法。
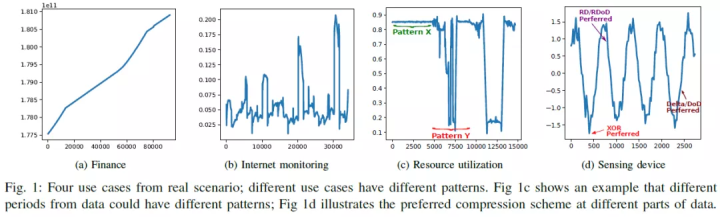
下图是阿里云业务中一些时序数据的示例,无损是从宏观还是微观层面,数据的 pattern 都是五花八门的,不仅仅是形状曲线,也包括数据精度等。所以压缩算法很有必要支持尽量多的一些压缩模式,然后又可以既有效又经济地选择其中一种进行压缩。
对于一个大型的商用的时序数据压缩算法,需要重点关注三个重要的特性:
- Time correlation:时序数据有很强的时间相关性,然后对应的数据基本上是连续的。采样间隔通常是 1s,100ms 等。
- Pattern diversity:如上图,pattern 及特性差距会很大。
- Data massiveness:每天、每小时、每秒需要处理的数据量都是海量的,总体处理数据至少是在每天 10P 的 level,对应的压缩算法需要高效且有高吞吐率。
2 新算法核心理念
追本溯源,数据压缩的本质可分为两阶段:首先 Transform 阶段把数据从一个空间转化到另外一个更规则的空间,然后在差值编码阶段用各种各样的办法较好的标识变换后的差值。
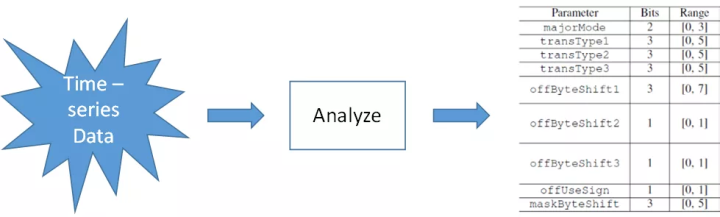
根据时序数据的特点,可以定义以下 6 个基本的 transform primitives(可扩展):

然后定义以下 3 种基本的 differential coding primitives(可扩展):

接下来把上面的两种 tools 排列组合进行压缩,这样可行但效果肯定不太好,因为模式选择和相关参数的 cost 比重太高了,需要 2B(primitive choice + primitive parameter)的控制信息,占了 8B 需要表达数据的 25%。
更好的方法应该是对数据的特性进行抽象化分层表达,示意图如下。创建一个控制参数集较好的表达所有的情况,然后在全局(一个 timeline)层面选择合适的参数来确定一个搜索空间(只包含少量的压缩模式,譬如 4 种);然后在具体进行每个点的压缩时,遍历从中选择出最好的那一种压缩模式进行压缩。控制信息的比重在 ~3%。

3 两阶段压缩框架AMMMO
AMMMO(adatpive multiple mode middle-out)整体过程分为两个阶段,第一阶段确定当前这条时间线的总体特性(确定 9 个控制参数的具体值);然后在第二阶段在少量的压缩模式中遍历并查找最后的一种进行压缩,具体框图如下:
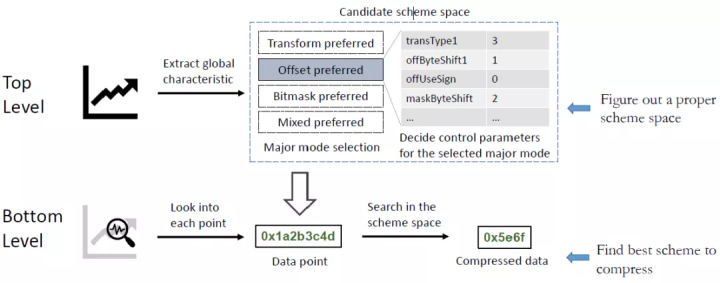
第二阶段的模式选择没有难度,逻辑简单适合高效率执行;第一阶段确定各参数值(9个这里)得到合适的压缩空间有比较大的挑战,需要从理论上的 300K 多个排列组合选择里找出合适的那一个。
4 基于规则的模式空间选择算法
可以设计一种算法,譬如创建各个压缩模式的效果记录牌(scoreboard),然后遍历一个 timeline 里的所有点并进行分析记录,然后再经过统计分析比较等选择最好的模式。一些显而易见的问题有:
- 选择的评估指标是否理想?
- 需要人工去思考并编写程序,有较多的实现,debug 和 maintain 的工作量。
- 如果算法中的 primitive,压缩模式等做了改变,整个代码都需要重构,基于上面的选择不是理论选择,需要一种自动且较智能的方法支撑不停的演化等。
深度强化学习
1 问题建模
简化上面的整个模式空间选择算法如下图,我们可以把这个问题等同于多目标的分类问题,每个参数就是一个目标,每个参数空间的取值范围就是可选择的类目数。深度学习在图像分类,语义理解等方面证明了它的高可用性。类似地,咱们也可以把这里的模式空间的选择问题用深度学习来实现,把它当做一个 multi-label 的 classification 问题。
用什么样的网络?考虑到识别的主要关系是 delta/xor, shift,bitmask 等为主,cnn 不恰当,full-connect 的 mlp 比较合适。相应地,把一条时间线上的所有点,如果 1 小时就是 3600 个共 3600*8B,有些太多,考虑到同一 timeline 内部一段一段的相似性,把 32 个点作为一个最基本的处理单元。
接下来,怎么去创建训练样本?怎么给样本寻找 label 呢?
在这里我们引入了强化学习,而不是有监督的学习去训练,因为:
1)去创建有 label 的样本很难
32 个样本 256B,理论上 sample 有 256^256 种可能性,对每个这种样本,需要遍历 300K 的可能性才能找出最好的那一个。创建及选择 sample,create label 的工作量都非常大。
2)这不是普通的 one-class-label 问题
给定一个样本,并不是有唯一的最好的一个结果,很有可能很多的选择都能取得相同的压缩效果,N class(N 基本不可知)的训练又增加了很多难度。
3)需要一种自动化的方法
压缩的 tool 等参数选择很有可能是需要扩展的,如果发生整个训练样本的创建等都需要重新再来。需要一种自动化的办法。
用什么样的强化学习呢?DQN,policy gradient,还是 actor-critic? 如前面分析,DQN 是不太适合 reward/action 不连续的的情况,这里的参数,譬如 majorMode 0 和 1 是完全不同的两种结果,所以 DQN 不合适。此外,压缩问题一方面不容易评价另外网络也没有那么复杂,不需要 actor-critic。最终我们选择了 policy gradient。
Policy gradient 常见的 loss 是用一个慢慢提高的 baseline 作为衡量标准来反馈当前的 action 是否合适,但这里并不太合适(效果尝试了也不太好),因为这里 sample 的理论 block(256^256)state 太多了一些。为此,我们专门设计了一个 loss。
得到了每个 block 的参数后,考虑到 block 的相关性等。可以用统计的办法,聚合得到整个 timeline 的最终参数设置。
2 深度强化学习网络框架
整体的网络框架示意图如下:
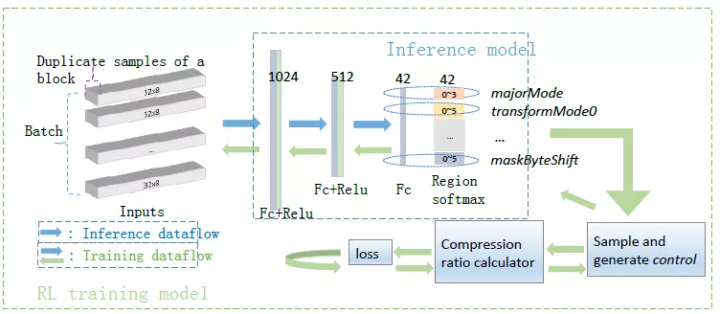
在训练端:随机选择 M 个 block,每个 block 复制 N 份,然后输入到有 3 个隐含层的全连接网络中,用 region softmax 得到各参数各种 choice 的概率,然后按照概率去 sample 每个参数的值,得到参数后输入到底层的压缩算法进行实际压缩并得到压缩值。复制的 N 个 block 相互比较计算 loss 然后做反向传播。loss 的整体设计为:
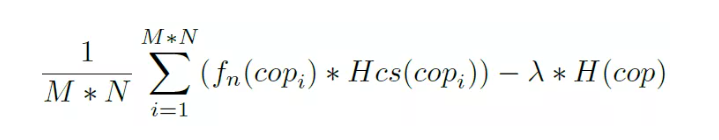
fn(copi) 描述了压缩效果,比 N 个 block 的均值高就正反馈,Hcs(copi) 是交叉熵,希望得分高的概率越大越确定越好;反之亦然。后面的 H(cop) 是交叉熵作为正则化因子来尽量避免网络固化且收敛到局部最优。
在推理端,可以把一个 timeline 的全部或局部 block 输入到网络中,得到参数,做统计聚合然后得到整个 timeline 的参数。
结果数据
1 实验设计
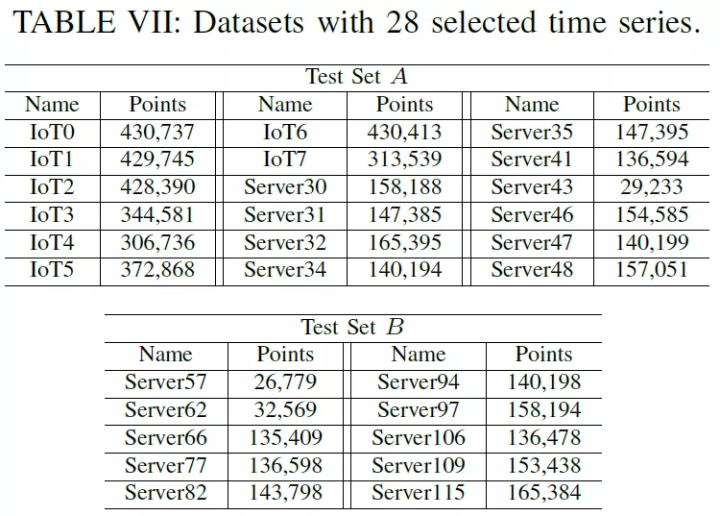
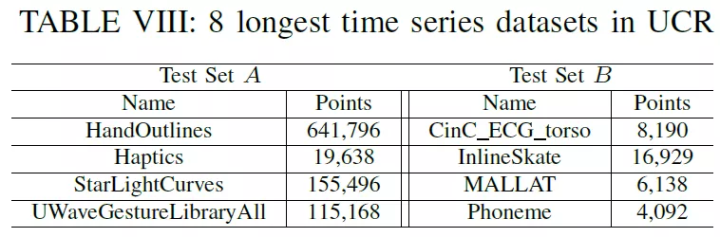
测试数据部分一方面随机选取了阿里云业务 IoT 和 server 两个大场景下共 28 个大的 timeline;另外也选取了时序数据分析挖掘领域最通用的数据集 UCR。基本信息如下:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java