
MySQL的MyISAM 引擎和Innodb 引擎的底层实现
Mysql 底层数据引擎以插件形式设计,最常见的是 Innodb 引擎和 Myisam 引擎,用户可以根据个人需求选择不同的引擎作为 Mysql 数据表的底层引擎。我们刚分析了,B+树作为 Mysql 的索引的数据结构非常合适,但是数据和索引到底怎么组织起来也是需要一番设计,设计理念的不同也导致了 Innodb 和 Myisam 的出现,各自呈现独特的性能。
MyISAM 虽然数据查找性能极佳,但是不支持事务处理。Innodb 最大的特色就是支持了 ACID 兼容的事务功能,而且他支持行级锁。Mysql 建立表的时候就可以指定引擎,比如下面的例子,就是分别指定了 Myisam 和 Innodb 作为 user 表和 user2 表的数据引擎。
两个引擎数据和索引的组织方式:
Innodb 创建表后生成的文件有:
- frm:创建表的语句
idb:表里面的数据+索引文件
Myisam 创建表后生成的文件有:
frm:创建表的语句
MYD:表里面的数据文件(myisam data)
MYI:表里面的索引文件(myisam index)
从生成的文件看来,这两个引擎底层数据和索引的组织方式并不一样,MyISAM 引擎把数据和索引分开了,一人一个文件,这叫做非聚集索引方式;Innodb 引擎把数据和索引放在同一个文件里了,这叫做聚集索引方式。下面将从底层实现角度分析这两个引擎是怎么依靠 B+树这个数据结构来组织引擎实现的。
MyISAM 引擎的底层实现(非聚集索引方式)
MyISAM 用的是非聚集索引方式,即数据和索引落在不同的两个文件上。MyISAM 在建表时以主键作为 KEY 来建立主索引 B+树,树的叶子节点存的是对应数据的物理地址。我们拿到这个物理地址后,就可以到 MyISAM 数据文件中直接定位到具体的数据记录了。
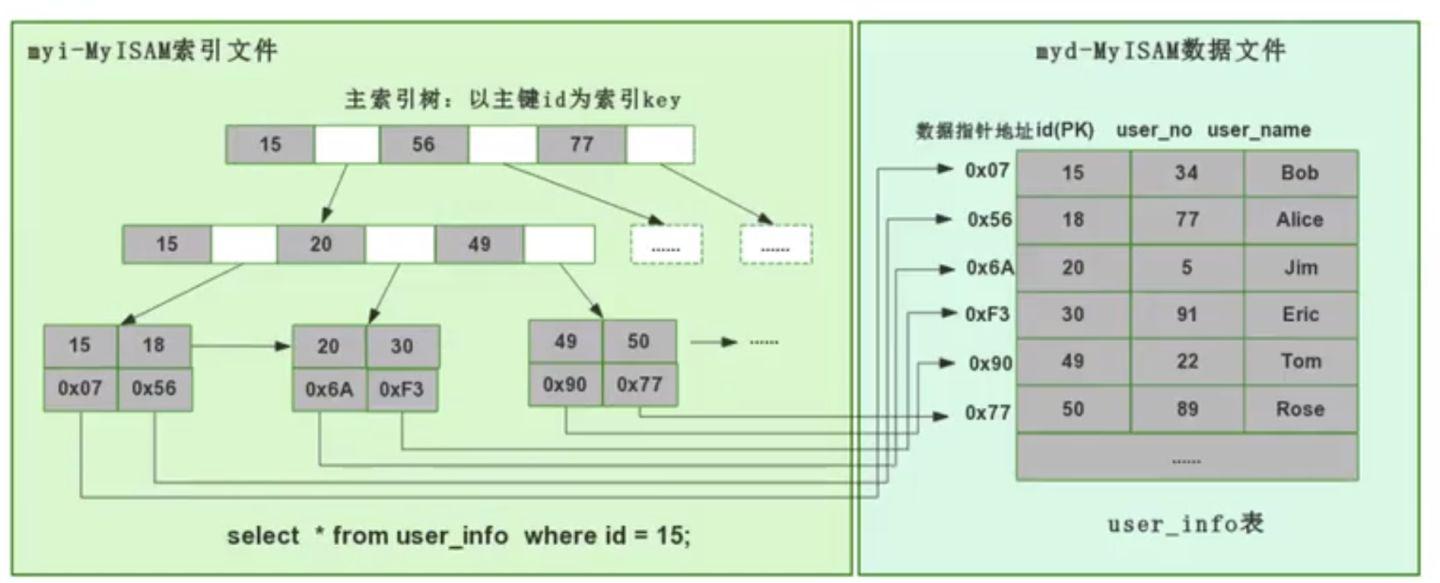
当我们为某个字段添加索引时,我们同样会生成对应字段的索引树,该字段的索引树的叶子节点同样是记录了对应数据的物理地址,然后也是拿着这个物理地址去数据文件里定位到具体的数据记录。
Innodb 引擎的底层实现(聚集索引方式)
InnoDB 是聚集索引方式,因此数据和索引都存储在同一个文件里。首先 InnoDB 会根据主键 ID 作为 KEY 建立索引 B+树,如左下图所示,而 B+树的叶子节点存储的是主键 ID 对应的数据,比如在执行 select * from user_info where id=15 这个语句时,InnoDB 就会查询这颗主键 ID 索引 B+树,找到对应的 user_name='Bob'。
这是建表的时候 InnoDB 就会自动建立好主键 ID 索引树,这也是为什么 Mysql 在建表时要求必须指定主键的原因。当我们为表里某个字段加索引时 InnoDB 会怎么建立索引树呢?比如我们要给 user_name 这个字段加索引,那么 InnoDB 就会建立 user_name 索引 B+树,节点里存的是 user_name 这个 KEY,叶子节点存储的数据的是主键 KEY。注意,叶子存储的是主键 KEY!拿到主键 KEY 后,InnoDB 才会去主键索引树里根据刚在 user_name 索引树找到的主键 KEY 查找到对应的数据。

问题来了,为什么 InnoDB 只在主键索引树的叶子节点存储了具体数据,但是其他索引树却不存具体数据呢,而要多此一举先找到主键,再在主键索引树找到对应的数据呢?
其实很简单,因为 InnoDB 需要节省存储空间。一个表里可能有很多个索引,InnoDB 都会给每个加了索引的字段生成索引树,如果每个字段的索引树都存储了具体数据,那么这个表的索引数据文件就变得非常巨大(数据极度冗余了)。从节约磁盘空间的角度来说,真的没有必要每个字段索引树都存具体数据,通过这种看似“多此一举”的步骤,在牺牲较少查询的性能下节省了巨大的磁盘空间,这是非常有值得的。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java