
Flink计算引擎方案和异常处理
Apache Flink 是当前广泛使用的计算引擎,是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
主要应用于实时监控、实时报表、流数据分析和实时仓库。
Flink 使用 checkpoint 机制进行容错处理,Flink 的 checkpoint 会将状态快照备份到分布式存储系统,供后续恢复使用。在 Alibaba 内部我们使用的存储主要是 HDFS,当同一个集群的 Job 到达一定数量后,会对 HDFS 造成非常大的压力,本文将介绍一种大幅度降低 HDFS 压力的方法 -- 小文件合并。
背景
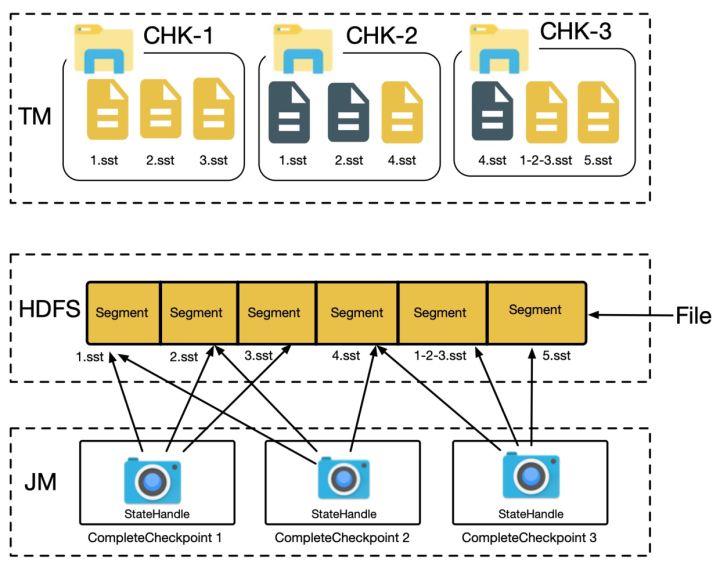
不管使用 FsStateBackend、RocksDBStateBackend 还是 NiagaraStateBackend,Flink 在进行 checkpoint 的时候,TM 会将状态快照写到分布式文件系统中,然后将文件句柄发给 JM,JM 完成全局 checkpoint 快照的存储,如下图所示。
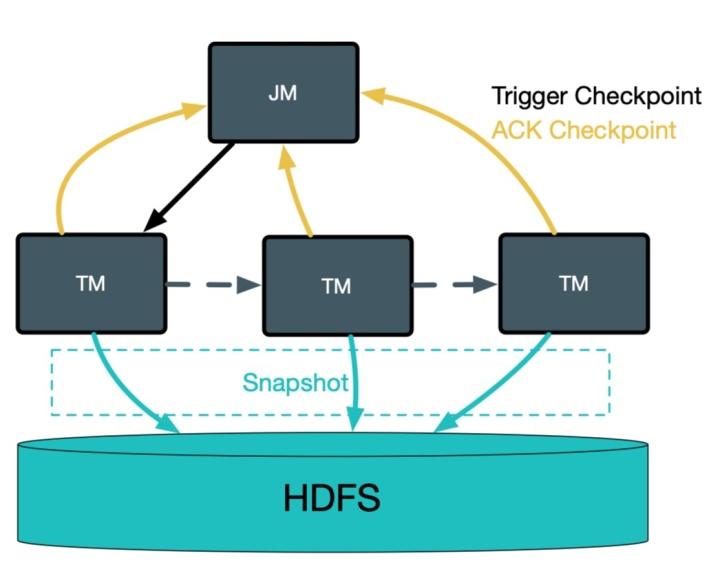
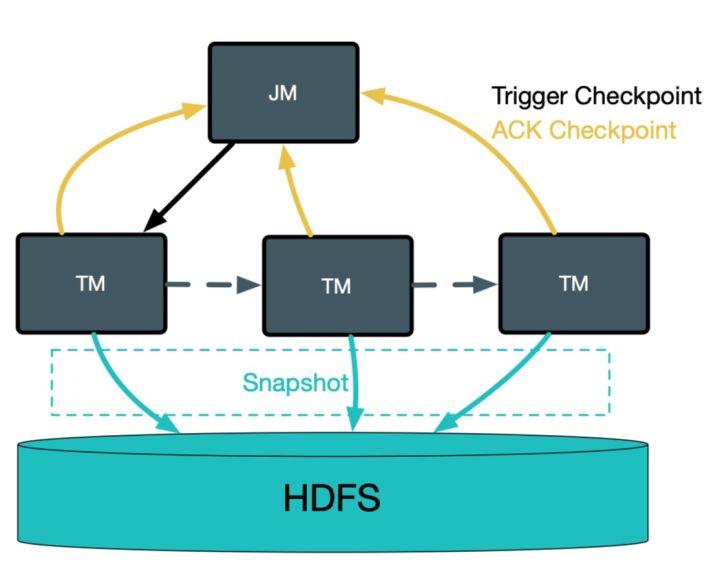
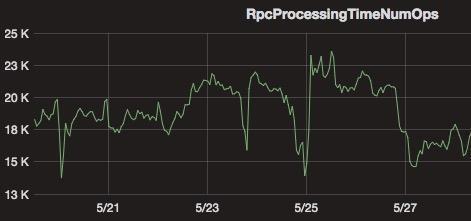
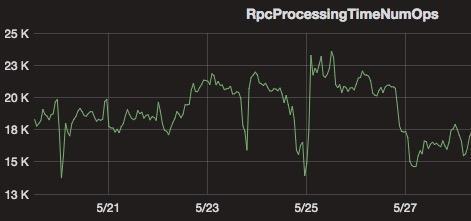
对于全量 checkpoint 来说,TM 将每个 checkpoint 内部的数据都写到同一个文件,而对于 RocksDBStateBackend/NiagaraStateBackend 的增量 checkpoint [2]来说,则会将每个 sst 文件写到一个分布式系统的文件内。当作业量很大,且作业的并发很大时,则会对底层 HDFS 形成非常大的压力:1)大量的 RPC 请求会影响 RPC 的响应时间(如下图所示);2)大量文件对 NameNode 内存造成很大压力。
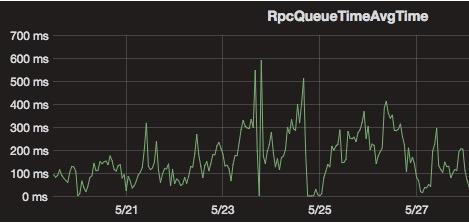

在 Flink 中曾经尝试使用 ByteStreamStateHandle 来解决小文件多的问题[3],将小于一定阈值的 state 直接发送到 JM,由 JM 统一写到分布式文件中,从而避免在 TM 端生成小文件。但是这个方案有一定的局限性,阈值设置太小,还会有很多小文件生成,阈值设置太大,则会导致 JM 内存消耗太多有 OOM 的风险。
1 小文件合并方案
针对上面的问题我们提出一种解决方案 -- 小文件合并。
在原来的实现中,每个 sst 文件会打开一个
CheckpointOutputStream,每个 CheckpointOutputStream 对应一个 FSDataOutputStream,将本地文件写往一个分布式文件,然后关闭 FSDataOutputStream,生成一个 StateHandle。如下图所示:
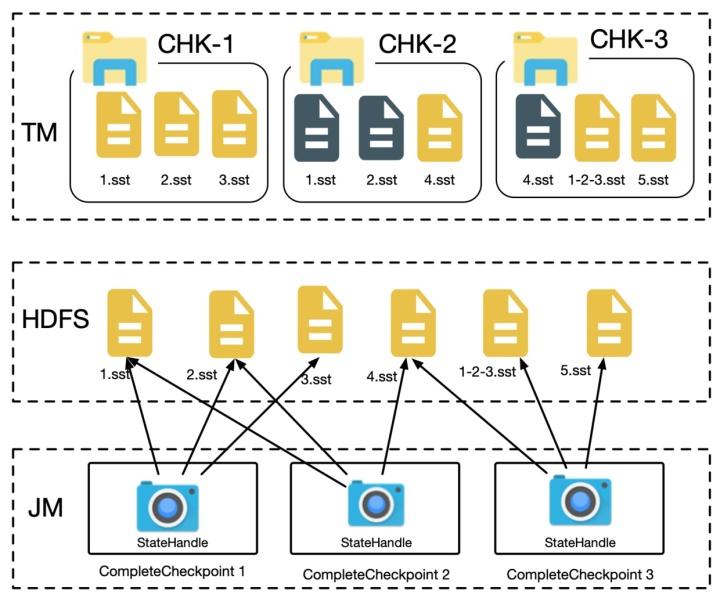
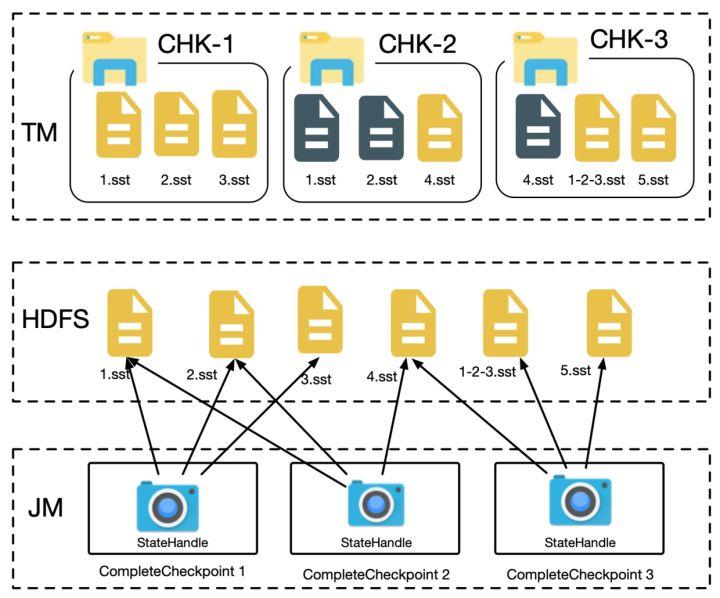
小文件合并则会重用打开的 FSDataOutputStream,直至文件大小达到预设的阈值为止,换句话说多个 sst 文件会重用同一个 DFS 上的文件,每个 sst 文件占用 DFS 文件中的一部分,最终多个 StateHandle 共用一个物理文件,如下图所示。
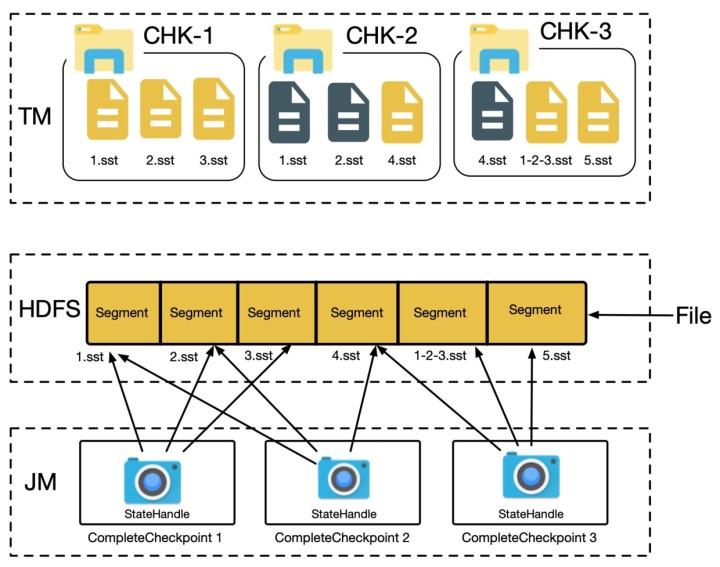
在接下来的章节中我们会描述实现的细节,其中需要重点考虑的地方包括:
并发 checkpoint 的支持
Flink 天生支持并发 checkpoint,小文件合并方案则会将多个文件写往同一个分布式存储文件中,如果考虑不当,数据会写串或者损坏,因此我们需要有一种机制保证该方案的正确性,详细描述参考 2.1 节防止误删文件
我们使用引用计数来记录文件的使用情况,仅通过文件引用计数是否降为 0 进行判断删除,则可能误删文件,如何保证文件不会被错误删除,我们将会在 2.2 节进行阐述降低空间放大
使用小文件合并之后,只要文件中还有一个 statehandle 被使用,整个分布式文件就不能被删除,因此会占用更多的空间,我们在 2.3 节描述了解决该问题的详细方案异常处理
我们将在 2.4 节阐述如何处理异常情况,包括 JM 异常和 TM 异常的情况2.5 节中会详细描述在 Checkpoint 被取消或者失败后,如何取消 TM 端的 Snapshot,如果不取消 TM 端的 Snapshot,则会导致 TM 端实际运行的 Snapshot 比正常的多
在第 3 节中阐述了小文件合并方案与现有方案的兼容性;第 4 节则会描述小文件合并方案的优势和不足;最后在第 5 节我们展示在生产环境下取得的效果。
2 设计实现
本节中我们会详细描述整个小文件合并的细节,以及其中的设计要点。
这里我们大致回忆一下 TM 端 Snapshot 的过程
TM 端 barrier 对齐
TM Snapshot 同步操作
TM Snapshot 异步操作
其中上传 sst 文件到分布式存储系统在上面的第三步,同一个 checkpoint 内的文件顺序上传,多个 checkpoint 的文件上传可能同时进行。
2.1 并发 checkpoint 支持
Flink 天生支持并发 checkpoint,因此小文件合并方案也需要能够支持并发 checkpoint,如果不同 checkpoint 的 sst 文件同时写往一个分布式文件,则会导致文件内容损坏,后续无法从该文件进行 restore。
在 FLINK-11937[4] 的提案中,我们会将每个 checkpoint 的 state 文件写到同一个 HDFS 文件,不同 checkpoint 的 state 写到不同的 HDFS 文件 -- 换句话说,HDFS 文件不跨 Checkpoint 共用,从而避免了多个客户端同时写入同一个文件的情况。
后续我们会继续推进跨 Checkpoint 共用文件的方案,当然在跨 Checkpoint 共用文件的方案中,并行的 Checkpoint 也会写往不同的 HDFS 文件。
2.2 防止误删文件
复用底层文件之后,我们使用引用计数追踪文件的使用情况,在文件引用数降为 0 的情况下删除文件。但是在某些情况下,文件引用数为 0 的时候,并不代表文件不会被继续使用,可能导致文件误删。下面我们会详>细描述开启并发 checkpoint 后可能导致文件误删的情况,以及解决方案。
我们以下图为例,maxConcurrentlyCheckpoint = 2
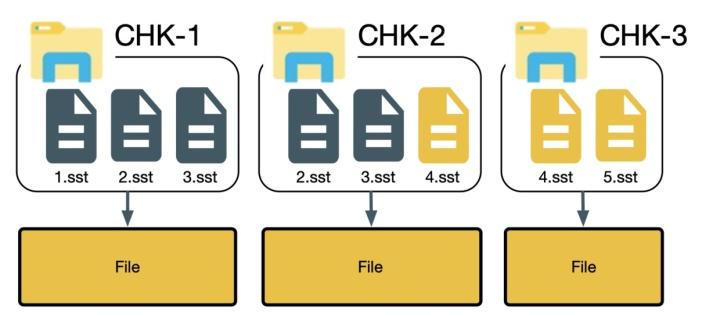
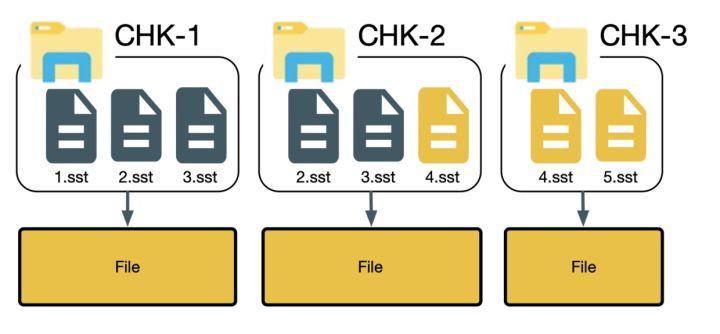
上图中共有 3 个 checkpoint,其中 chk-1 已经完成,chk-2 和 chk-3 都基于 chk-1 进行,chk-2 在 chk-3 前完成,chk-3 在注册 4.sst 的时候发现,发现 4.sst 在 chk-2 中已经注册过,会重用 chk-2 中 4.sst 对应的 stateHandle,然后取消 chk-3 中的 4.sst 的注册,并且删除 stateHandle,在处理完 chk-3 中 4.sst 之后,该 stateHandle 对应的分布式文件的引用计数为 0,如果我们这个时候删除分布式文件,则会同时删除 5.sst 对应的内容,导致后续无法从 chk-3 恢复。
这里的问题是如何在 stateHandle 对应的分布式文件引用计数降为 0 的时候正确判断是否还会继续引用该文件,因此在整个 checkpoint 完成处理之后再判断某个分布式文件能否删除,如果真个 checkpoint 完成发现文件没有被引用,则可以安全删除,否则不进行删除。
2.3 降低空间放大
使用小文件合并方案后,每个 sst 文件对应分布式文件中的一个 segment,如下图所示
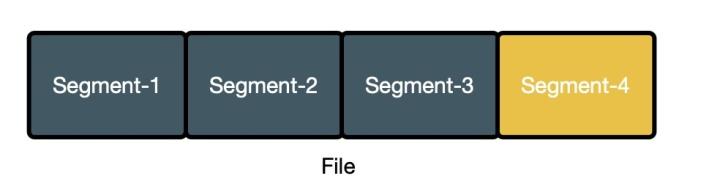
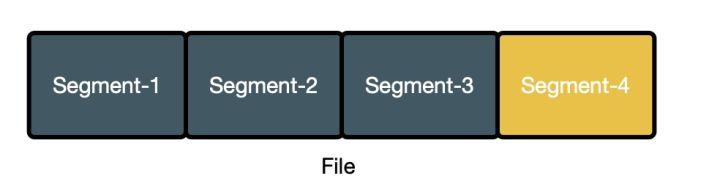
文件仅能在所有 segment 都不再使用时进行删除,上图中有 4 个 segment,仅 segment-4 被使用,但是整个文件都不能删除,其中 segment[1-3] 的空间被浪费掉了,从实际生产环境中的数据可知,整体的空间放大率(实际占用的空间 / 真实有用的空间)在 1.3 - 1.6 之间。
为了解决空间放大的问题,在 TM 端起异步线程对放大率超过阈值的文件进行压缩。而且仅对已经关闭的文件进行压缩。
整个压缩的流程如下所示:
计算每个文件的放大率
如果放大率较小则直接跳到步骤 7
如果文件 A 的放大率超过阈值,则生成一个对应的新文件 A‘(如果这个过程中创建文件失败,则由 TM 负责清理工作)
记录 A 与 A’ 的映射关系
在下一次 checkpoint X 往 JM 发送落在文件 A 中的 StateHandle 时,则使用 A` 中的信息生成一个新的 StateHandle 发送给 JM
checkpoint X 完成后,我们增加 A‘ 的引用计数,减少 A 的引用计数,在引用计数降为 0 后将文件 A 删除(如果 JM 增加了 A’ 的引用,然后出现异常,则会从上次成功的 checkpoint 重新构建整个引用计数器)
文件压缩完成
2.4 异常情况处理
在 checkpoint 的过程中,主要有两种异常:JM 异常和 TM 异常,我们将分情况阐述。
2.4.1 JM 异常
JM 端主要记录 StateHandle 以及文件的引用计数,引用计数相关数据不需要持久化到外存中,因此不需要特殊的处理,也不需要考虑 transaction 等相关操作,如果 JM 发送 failover,则可以直接从最近一次 complete checkpoint 恢复,并重建引用计数即可。
2.4.2 TM 异常
TM 异常可以分为两种:1)该文件在之前 checkpoint 中已经汇报过给 JM;2)文件尚未汇报过给 JM,我们会分情况阐述。
文件已经汇报过给 JM
文件汇报过给 JM,因此在 JM 端有文件的引用计数,文件的删除由 JM 控制,当文件的引用计数变为 0 之后,JM 将删除该文件。文件尚未汇报给 JM
该文件暂时尚未汇报过给 JM,该文件不再被使用,也不会被 JM 感知,成为孤儿文件。这种情况暂时有外围工具统一进行清理。
2.5 取消 TM 端 snapshot
像前面章节所说,我们需要在 checkpoint 超时/失败时,取消 TM 端的 snapshot,而 Flink 则没有相应的通知机制,现在 FLINK-8871[5] 在追踪相应的优化,我们在内部增加了相关实现,当 checkpoint 失败时会发送 RPC 数据给 TM,TM 端接受到相应的 RPC 消息后,会取消相应的 snapshot。
3 兼容性
小文件合并功能支持从之前的版本无缝迁移过来。从之前的 checkpoint restore 的的步骤如下:
每个 TM 分到自己需要 restore 的 state handle
TM 从远程下载 state handle 对应的数据
从本地进行恢复
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java