Table of Contents
This chapter covers MySQL InnoDB cluster, which combines MySQL technologies to enable you to create highly available clusters of MySQL server instances.
MySQL InnoDB cluster provides a complete high availability solution for MySQL. MySQL Shell includes AdminAPI which enables you to easily configure and administer a group of at least three MySQL server instances to function as an InnoDB cluster. Each MySQL server instance runs MySQL Group Replication, which provides the mechanism to replicate data within InnoDB clusters, with built-in failover. AdminAPI removes the need to work directly with Group Replication in InnoDB clusters, but for more information see Chapter 18, Group Replication which explains the details. MySQL Router can automatically configure itself based on the cluster you deploy, connecting client applications transparently to the server instances. In the event of an unexpected failure of a server instance the cluster reconfigures automatically. In the default single-primary mode, an InnoDB cluster has a single read-write server instance - the primary. Multiple secondary server instances are replicas of the primary. If the primary fails, a secondary is automatically promoted to the role of primary. MySQL Router detects this and forwards client applications to the new primary. Advanced users can also configure a cluster to have multiple-primaries.
InnoDB cluster does not provide support for MySQL NDB Cluster.
NDB Cluster depends on the NDB storage
engine as well as a number of programs specific to NDB Cluster which
are not furnished with MySQL Server 8.0;
NDB is available only as part of the MySQL
NDB Cluster distribution. In addition, the MySQL server binary
(mysqld) that is supplied with MySQL Server
8.0 cannot be used with NDB Cluster. For more
information about MySQL NDB Cluster, see
Chapter 22, MySQL NDB Cluster 8.0.
Section 22.1.6, “MySQL Server Using InnoDB Compared with NDB Cluster”, provides information
about the differences between the InnoDB and
NDB storage engines.
The following diagram shows an overview of how these technologies work together:
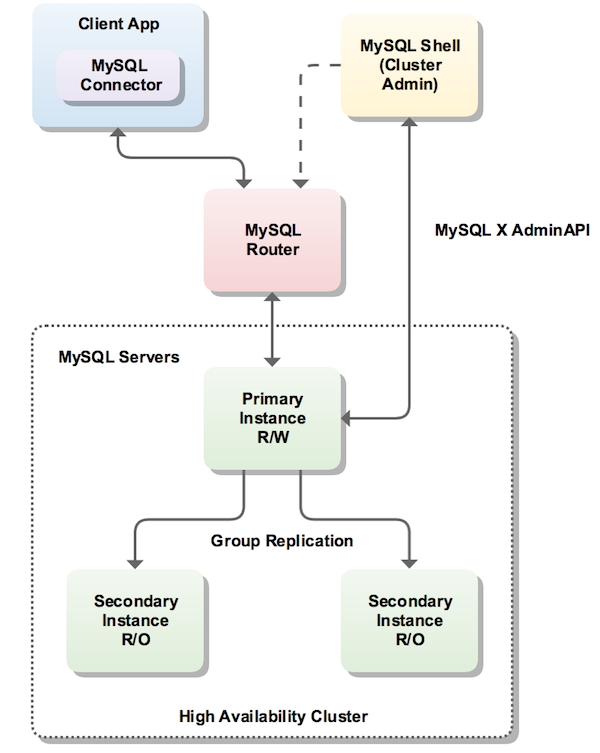
MySQL Shell includes the AdminAPI, which is accessed
through the dba global variable and its
associated methods. The dba variable's
methods enable you to deploy, configure, and administer InnoDB
clusters. For example, use the
dba.createCluster() method to create an
InnoDB cluster.
MySQL Shell enables you to connect to servers over a socket connection, but AdminAPI requires TCP connections to a server instance. Socket based connections are not supported in AdminAPI.
MySQL Shell provides online help for the AdminAPI. To
list all available dba commands, use the
dba.help() method. For online help on a
specific method, use the general format
object.help('methodname'). For example:
mysql-js> dba.help('getCluster')
Retrieves a cluster from the Metadata Store.
SYNTAX
dba.getCluster([name][, options])
WHERE
name: Parameter to specify the name of the cluster to be returned.
options: Dictionary with additional options.
RETURNS
The cluster object identified by the given name or the default cluster.
DESCRIPTION
If name is not specified or is null, the default cluster will be returned.
If name is specified, and no cluster with the indicated name is found, an error
will be raised.
The options dictionary accepts the connectToPrimary option,which defaults to
true and indicates the shell to automatically connect to the primary member of
the cluster.
EXCEPTIONS
MetadataError in the following scenarios:
- If the Metadata is inaccessible.
- If the Metadata update operation failed.
ArgumentError in the following scenarios:
- If the Cluster name is empty.
- If the Cluster name is invalid.
- If the Cluster does not exist.
RuntimeError in the following scenarios:
- If the current connection cannot be used for Group Replication.
This section explains the different ways you can create an InnoDB cluster, the requirements for server instances and the software you need to install to deploy a cluster.
InnoDB cluster supports the following deployment scenarios:
Production deployment: if you want to use InnoDB cluster in a full production environment you need to configure the required number of machines and then deploy your server instances to the machines. A production deployment enables you to exploit the high availability features of InnoDB cluster to their full potential. See Section 21.2.4, “Production Deployment of InnoDB Cluster” for instructions.
Sandbox deployment: if you want to test out InnoDB cluster before committing to a full production deployment, the provided sandbox feature enables you to quickly set up a cluster on your local machine. Sandbox server instances are created with the required configuration and you can experiment with InnoDB cluster to become familiar with the technologies employed. See Section 21.2.6, “Sandbox Deployment of InnoDB Cluster” for instructions.
ImportantA sandbox deployment is not suitable for use in a full production environment.
Before installing a production deployment of InnoDB cluster, ensure that the server instances you intend to use meet the following requirements.
InnoDB cluster uses Group Replication and therefore your server instances must meet the same requirements. See Section 18.9.1, “Group Replication Requirements”. AdminAPI provides the
dba.checkInstanceConfiguration()method to verify that an instance meets the Group Replication requirements, and thedba.configureInstance()method to configure an instance to meet the requirements.NoteWhen using a sandbox deployment the instances are configured to meet these requirements automatically.
Group Replication members can contain tables using a storage engine other than
InnoDB, for exampleMyISAM. Such tables cannot be written to by Group Replication, and therefore when using InnoDB cluster. To be able to write to such tables with InnoDB cluster, convert all such tables toInnoDBbefore using the instance in a InnoDB cluster.The Performance Schema must be enabled on any instance which you want to use with InnoDB cluster.
The provisioning scripts that MySQL Shell uses to configure servers for use in InnoDB cluster require access to Python version 2.7. For a sandbox deployment Python is required on the single machine used for the deployment, production deployments require Python on each server instance which should run MySQL Shell locally, see Persisting Settings.
On Windows MySQL Shell includes Python and no user configuration is required. On Unix Python must be found as part of the shell environment. To check that your system has Python configured correctly issue:
$
/usr/bin/env pythonIf a Python interpreter starts, no further action is required. If the previous command fails, create a soft link between
/usr/bin/pythonand your chosen Python binary.From version 8.0.17, instances must use a unique
server_idwithin a InnoDB cluster. When you use theCluster.addInstance(instance)server_idofinstanceis already used by an instance in the cluster then the operation fails with an error.
The method you use to install InnoDB cluster depends on the type of deployment you intend to use. For a sandbox deployment install the components of InnoDB cluster to a single machine. A sandbox deployment is local to a single machine, therefore the install needs to only be done once on the local machine. For a production deployment install the components to each machine that you intend to add to your cluster. A production deployment uses multiple remote host machines running MySQL server instances, so you need to connect to each machine using a tool such as SSH or Windows remote desktop to carry out tasks such as installing components. The following methods of installing InnoDB cluster are available:
Downloading and installing the components using the following documentation:
MySQL Server - see Chapter 2, Installing and Upgrading MySQL.
MySQL Shell - see Installing MySQL Shell.
MySQL Router - see Installing MySQL Router.
On Windows you can use the MySQL Installer for Windows for a sandbox deployment. For details, see Section 2.3.3.3.1.1, “High Availability”.
Once you have installed the software required by InnoDB cluster choose to follow either Section 21.2.6, “Sandbox Deployment of InnoDB Cluster” or Section 21.2.4, “Production Deployment of InnoDB Cluster”.
When working in a production environment, the MySQL server instances which make up an InnoDB cluster run on multiple host machines as part of a network rather than on single machine as described in Section 21.2.6, “Sandbox Deployment of InnoDB Cluster”. Before proceeding with these instructions you must install the required software to each machine that you intend to add as a server instance to your cluster, see Section 21.2.3, “Methods of Installing”.
The following diagram illustrates the scenario you work with in this section:
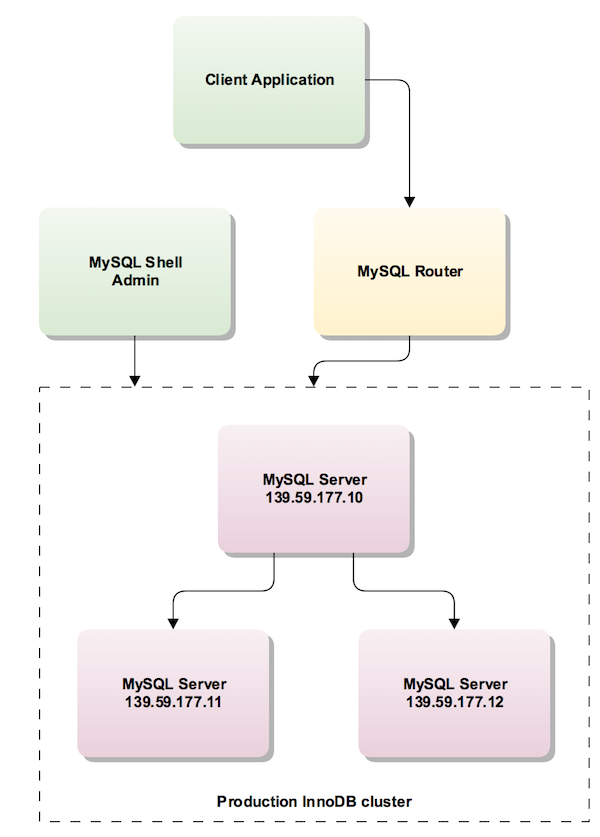
Unlike a sandbox deployment, where all instances are deployed locally to one machine which AdminAPI has local file access to and can persist configuration changes, for a production deployment you must persist any configuration changes on the instance. How you do this depends on the version of MySQL running on the instance, see Persisting Settings.
To pass a server's connection information to AdminAPI, use URI-like connection strings or a data dictionary; see Section 4.2.5, “Connecting to the Server Using URI-Like Strings or Key-Value Pairs”. In this documentation, URI-like strings are shown.
The following sections describe how to deploy a production InnoDB cluster.
The user account used to administer an instance does not have
to be the root account, however the user needs to be assigned
full read and write privileges on the InnoDB cluster
metadata tables in addition to full MySQL administrator
privileges (SUPER, GRANT
OPTION, CREATE,
DROP and so on). The preferred method to
create users to administer the cluster is using the
clusterAdmin option with the
dba.configureInstance(), and
Cluster.addInstance()ic
is shown in examples.
If only read operations are needed (such as for monitoring purposes), an account with more restricted privileges can be used. See Configuring Users for InnoDB Cluster.
As part of using Group Replication, InnoDB cluster creates
internal users which enable replication between the servers in
the cluster. These users are internal to the cluster, and the
user name of the generated users follows a naming scheme of
mysql_innodb_cluster_r[.
The hostname used for the internal users depends on whether
the 10_numbers]ipWhitelist option has been configured.
If ipWhitelist is not configured, it
defaults to AUTOMATIC and the internal
users are created using both the wildcard %
character and localhost for the hostname
value. When ipWhitelist has been
configured, for each address in the
ipWhitelist list an internal user is
created.
For more information, see
Creating a Whitelist of Servers.
Each internal user has a randomly generated password. The randomly generated users are given the following grants:
GRANT REPLICATION SLAVE ON *.* to internal_user;The internal user accounts are created on the seed instance and then replicated to the other instances in the cluster. The internal users are:
generated when creating a new cluster by issuing
dba.createCluster()generated when adding a new instance to the cluster by issuing
Cluster.addInstance()
In addition, the
Cluster.rejoinInstance()ipWhitelist option is
used to specify a hostname. For example by issuing:
Cluster.rejoinInstance({ipWhitelist: "192.168.1.1/22"});
all previously existing internal users are removed and a new
internal user is created, taking into account the
ipWhitelist value used.
For more information on the internal users required by Group Replication, see Section 18.2.1.3, “User Credentials”.
The production instances which make up a cluster run on separate machines, therefore each machine must have a unique host name and be able to resolve the host names of the other machines which run server instances in the cluster. If this is not the case, you can:
configure each machine to map the IP of each other machine to a hostname. See your operating system documentation for details. This is the recommended solution.
set up a DNS service
configure the
report_hostvariable in the MySQL configuration of each instance to a suitable externally reachable address
InnoDB cluster supports using IP addresses instead of host names, and addresses must be specified in IPv4 format.
In this procedure the host name
ic- is
used in examples.
number
To verify whether the hostname of a MySQL server is correctly configured, execute the following query to see how the instance reports its own address to other servers and try to connect to that MySQL server from other hosts using the returned address:
SELECT coalesce(@@report_host, @@hostname);
The AdminAPI commands you use to work with a cluster
and it's server instances modify the configuration of the
instance. Depending on the way MySQL Shell is connected to
the instance and the version of MySQL installed on the
instance, these configuration changes can be persisted to the
instance automatically. Persisting settings to the instance
ensures that configuration changes are retained after the
instance restarts, for background information see
SET
PERSIST. This is essential for reliable cluster
usage, for example if settings are not persisted then an
instance which has been added to a cluster does not rejoin the
cluster after a restart because configuration changes are
lost. Persisting changes is required after the following
operations:
dba.configureInstance()dba.createCluster()Cluster.addInstance()Cluster.removeInstance()Cluster.rejoinInstance()
Instances which meet the following requirements support persisting configuration changes automatically:
the instance is running MySQL version 8.0.11 or later
persisted_globals_loadis set toON
Instances which do not meet these requirements do not support persisting configuration changes automatically, when AdminAPI operations result in changes to the instance's settings to be persisted you receive warnings such as:
WARNING: On instance 'localhost:3320' membership change cannot be persisted since MySQL version 5.7.21 does not support the SET PERSIST command (MySQL version >= 8.0.5 required). Please use the <Dba>.configureLocalInstance command locally to persist the changes.
When AdminAPI commands are issued against the MySQL
instance which MySQL Shell is currently running on, in other
words the local instance, MySQL Shell persists configuration
changes directly to the instance. On local instances which
support persisting configuration changes automatically,
configuration changes are persisted to the instance's
mysqld-auto.cnf file and the
configuration change does not require any further steps. On
local instances which do not support persisting configuration
changes automatically, you need to make the changes locally,
see Configuring Instances with
dba.configureLocalInstance().
When run against a remote instance, in other words an instance
other than the one which MySQL Shell is currently running
on, if the instance supports persisting configuration changes
automatically, the AdminAPI commands persist
configuration changes to the instance's
mysql-auto.conf option file. If a remote
instance does not support persisting configuration changes
automatically, the AdminAPI commands can not
automatically configure the instance's option file. This means
that AdminAPI commands can read information from the
instance, for example to display the current configuration,
but changes to the configuration cannot be persisted to the
instance's option file. In this case, you need to persist the
changes locally, see
Configuring Instances with
dba.configureLocalInstance().
When working with a production deployment it can be useful to
configure verbose logging for MySQL Shell, the information
in the log can help you to find and resolve any issues that
might occur when you are preparing server instances to work as
part of InnoDB cluster. To start MySQL Shell with a
verbose logging level use the
--log-level option:
shell> mysqlsh --log-level=DEBUG3
The DEBUG3 is recommended, see
--log-level for more
information. When DEBUG3 is set the
MySQL Shell log file contains lines such as Debug:
execute_sql( ... ) which contain the SQL queries
that are executed as part of each AdminAPI call. The
log file generated by MySQL Shell is located in
~/.mysqlsh/mysqlsh.log for Unix-based
systems; on Microsoft Windows systems it is located in
%APPDATA%\MySQL\mysqlsh\mysqlsh.log. See
MySQL Shell Logging and Debug for more
information.
In addition to enabling the MySQL Shell log level, you can configure the amount of output AdminAPI provides in MySQL Shell after issuing each command. To enable the amount of AdminAPI output, in MySQL Shell issue:
mysql-js> dba.verbose=2
This enables the maximum output from AdminAPI calls. The available levels of output are:
0 or OFF is the default. This provides minimal output and is the recommended level when not troubleshooting.
1 or ON adds verbose output from each call to the AdminAPI.
2 adds debug output to the verbose output providing full information about what each call to AdminAPI executes.
AdminAPI provides the
dba.configureInstance() function that
checks if an instance is suitably configured for
InnoDB cluster usage, and configures the instance if it
finds any settings which are not compatible with
InnoDB cluster. You run the
dba.configureInstance() command against an
instance and it checks all of the settings required to enable
the instance to be used for InnoDB cluster usage. If the
instance does not require configuration changes, there is no
need to modify the configuration of the instance, and the
dba.configureInstance() command output
confirms that the instance is ready for InnoDB cluster
usage. If any changes are required to make the instance
compatible with InnoDB cluster, a report of the incompatible
settings is displayed, and you can choose to let the command
make the changes to the instance's option file. Depending on
the way MySQL Shell is connected to the instance, and the
version of MySQL running on the instance, you can make these
changes permanent by persisting them to a remote instance's
option file, see
Persisting Settings.
Instances which do not support persisting configuration
changes automatically require that you configure the instance
locally, see Configuring Instances with
dba.configureLocalInstance().
Alternatively you can make the changes to the instance's
option file manually, see Section 4.2.2.2, “Using Option Files” for
more information. Regardless of the way you make the
configuration changes, you might have to restart MySQL to
ensure the configuration changes are detected.
The syntax of the dba.configureInstance()
command is:
dba.configureInstance([instance][,options])
where instance is an instance
definition, and options is a data
dictionary with additional options to configure the operation.
The command returns a descriptive text message about the
operation's result.
The instance definition is the
connection data for the instance, see
Section 4.2.5, “Connecting to the Server Using URI-Like Strings or Key-Value Pairs”. If
the target instance already belongs to an InnoDB cluster an
error is generated and the process fails.
The options dictionary can contain the following:
mycnfPath- the path to the MySQL option file of the instance.outputMycnfPath- alternative output path to write the MySQL option file of the instance.password- the password to be used by the connection.clusterAdmin- the name of an InnoDB cluster administrator user to be created. The supported format is the standard MySQL account name format. Supports identifiers or strings for the user name and host name. By default if unquoted it assumes input is a string.clusterAdminPassword- the password for the InnoDB cluster administrator account being created usingclusterAdmin.clearReadOnly- a boolean value used to confirm thatsuper_read_onlyshould be set to off, see Super Read-only and Instances.interactive- a boolean value used to disable the interactive wizards in the command execution, so that prompts are not provided to the user and confirmation prompts are not shown.restart- a boolean value used to indicate that a remote restart of the target instance should be performed to finalize the operation.
Although the connection password can be contained in the instance definition, this is insecure and not recommended. Use the MySQL Shell Pluggable Password Store to store instace passwords securely.
Once dba.configureInstance() is issued
against an instance, the command checks if the instance's
settings are suitable for InnoDB cluster usage. A report is
displayed which shows the settings required by
InnoDB cluster
. If the instance does not require any changes to its settings
you can use it in an InnoDB cluster, and can proceed to
Creating the Cluster. If the instance's settings
are not valid for InnoDB cluster usage the
dba.configureInstance() command displays
the settings which require modification. Before configuring
the instance you are prompted to confirm the changes shown in
a table with the following information:
Variable- the invalid configuration variable.Current Value- the current value for the invalid configuration variable.Required Value- the required value for the configuration variable.
How you proceed depends on whether the instance supports
persisting settings, see
Persisting Settings.
When dba.configureInstance() is issued
against the MySQL instance which MySQL Shell is currently
running on, in other words the local instance, it attempts to
automatically configure the instance. When
dba.configureInstance() is issued against a
remote instance, if the instance supports persisting
configuration changes automatically, you can choose to do
this.
If a remote instance does not support persisting the changes
to configure it for InnoDB cluster usage, you have to
configure the instance locally. See
Configuring Instances with
dba.configureLocalInstance().
In general, a restart of the instance is not required after
dba.configureInstance() configures the
option file, but for some specific settings a restart might be
required. This information is shown in the report generated
after issuing dba.configureInstance(). If
the instance supports the
RESTART statement,
MySQL Shell can shutdown and then start the instance. This
ensures that the changes made to the instance's option file
are detected by mysqld. For more information see
RESTART.
After executing a RESTART
statement, the current connection to the instance is lost.
If auto-reconnect is enabled, the connection is
reestablished after the server restarts. Otherwise, the
connection must be reestablished manually.
The dba.configureInstance() method verifies
that a suitable user is available for cluster usage, which is
used for connections between members of the cluster, see
User Privileges. The
recommended way to add a suitable user is to use the
clusterAdmin and
clusterAdminPassword options, which enable
you to configure the cluster user and password when calling
the function. For example:
mysql-js> dba.configureInstance('ic@ic-1:3306', \
{clusterAdmin: "'icadmin'@'ic-1%'", clusterAdminPassword: 'password'});This user is granted the privileges to be able to administer the cluster. The format of the user names accepted follows the standard MySQL account name format, see Section 6.2.4, “Specifying Account Names”.
If you do not specify a user to administer the cluster, in interactive mode a wizard enables you to choose one of the following options:
enable remote connections for the root user
create a new user, the equivalent of specifying the
clusterAdminandclusterAdminPasswordoptionsno automatic configuration, in which case you need to manually create the user
The following example demonstrates the option to create a new user for cluster usage.
mysql-js> dba.configureLocalInstance('root@localhost:3306')
Please provide the password for 'root@localhost:3306':
Please specify the path to the MySQL configuration file: /etc/mysql/mysql.conf.d/mysqld.cnf
Validating instance...
The configuration has been updated but it is required to restart the server.
{
"config_errors": [
{
"action": "restart",
"current": "OFF",
"option": "enforce_gtid_consistency",
"required": "ON"
},
{
"action": "restart",
"current": "OFF",
"option": "gtid_mode",
"required": "ON"
},
{
"action": "restart",
"current": "0",
"option": "log_bin",
"required": "1"
},
{
"action": "restart",
"current": "0",
"option": "log_slave_updates",
"required": "ON"
},
{
"action": "restart",
"current": "FILE",
"option": "master_info_repository",
"required": "TABLE"
},
{
"action": "restart",
"current": "FILE",
"option": "relay_log_info_repository",
"required": "TABLE"
},
{
"action": "restart",
"current": "OFF",
"option": "transaction_write_set_extraction",
"required": "XXHASH64"
}
],
"errors": [],
"restart_required": true,
"status": "error"
}
mysql-js>
If the instance has
super_read_only=ON then you
might need to confirm that AdminAPI can set
super_read_only=OFF. See
Super Read-only and Instances for more
information.
Once you have prepared your instances, use the
dba.createCluster() function to create the
cluster. The machine which you are running MySQL Shell on is
used as the seed instance for the cluster. The seed instance
is replicated to the other instances which you add to the
cluster, making them replicas of the seed instance.
MySQL Shell must be connected to an instance before you can
create a cluster because when you issue
dba.createCluster(
MySQL Shell creates a MySQL protocol session to the server
instance connected to the MySQL Shell's current global
session. Use the
name)dba.createCluster(
function to create the cluster and assign the returned cluster
to a variable called name)cluster:
mysql-js> var cluster = dba.createCluster('testCluster')
Validating instance at ic@ic-1:3306...
This instance reports its own address as ic-1
Instance configuration is suitable.
Creating InnoDB cluster 'testCluster' on 'ic@ic-1:3306'...
Adding Seed Instance...
Cluster successfully created. Use Cluster.addInstance() to add MySQL instances.
At least 3 instances are needed for the cluster to be able to withstand up to
one server failure.
The returned Cluster object uses a new session, independent from the MySQL Shell's main session. This ensures that if you change the MySQL Shell global session, the Cluster object maintains its session to the instance.
The dba.createCluster() operation supports
MySQL Shell's interactive option. When
interactive is on, prompts appear in the
following situations:
when run on an instance that belongs to a cluster and the
adoptFromGroption is false, you are asked if you want to adopt an existing clusterwhen the
forceoption is not used (not set totrue), you are asked to confirm the creation of a multi-primary cluster
If you encounter an error related to metadata being inaccessible you might have the loopback network interface configured. For correct InnoDB cluster usage disable the loopback interface.
To check the cluster has been created, use the cluster
instance's status() function. See
Checking a cluster's Status with
Cluster.status()
Once server instances belong to a cluster it is important to
only administer them using MySQL Shell and
AdminAPI. Attempting to manually change the
configuration of Group Replication on an instance once it
has been added to a cluster is not supported. Similarly,
modifying server variables critical to InnoDB cluster,
such as server_uuid after
an instance is configured using AdminAPI is not
supported.
When you create a cluster using MySQL Shell 8.0.14 and
later, you can set the timeout before instances are expelled
from the cluster, for example when they become unreachable.
Pass the expelTimeout option to the
dba.createCluster() operation, which
configures the
group_replication_member_expel_timeout
variable on the seed instance. The
expelTimeout option can take an integer
value in the range of 0 to 3600. All instances running MySQL
server 8.0.13 and later which are added to a cluster with
expelTimeout configured are automatically
configured to have the same expelTimeout
value as configured on the seed instance.
For information on the other options which you can pass to
dba.createCluster(), see
Section 21.4, “Working with InnoDB Cluster”.
Use the
Cluster.addInstance(instance)instance is connection information
to a configured instance, see
Configuring Production Instances. From
version 8.0.17, Group Replication implements compatibility
policies which consider the patch version of the instances,
and the
Cluster.addInstance()
You need a minimum of three instances in the cluster to make it tolerant to the failure of one instance. Adding further instances increases the tolerance to failure of an instance. To add an instance to the cluster issue:
mysql-js> cluster.addInstance('ic@ic-2:3306')
A new instance will be added to the InnoDB cluster. Depending on the amount of
data on the cluster this might take from a few seconds to several hours.
Please provide the password for 'ic@ic-2:3306': ********
Adding instance to the cluster ...
Validating instance at ic-2:3306...
This instance reports its own address as ic-2
Instance configuration is suitable.
The instance 'ic@ic-2:3306' was successfully added to the cluster.
If you are using MySQL 8.0.17 or later you can choose how the instance recovers the transactions it requires to synchronize with the cluster. Only when the joining instance has recovered all of the transactions previously processed by the cluster can it then join as an online instance and begin processing transactions. For more information, see Section 21.2.5, “Using MySQL Clone with InnoDB cluster”.
Also in 8.0.17 and later, you can configure how
Cluster.addInstance()
Depending on which option you chose to recover the instance from the cluster, you see different output in MySQL Shell. Suppose that you are adding the instance ic-2 to the cluster, and ic-1 is the seed or donor.
When you use MySQL Clone to recover an instance from the cluster, the output looks like:
Validating instance at ic-2:3306... This instance reports its own address as ic-2:3306 Instance configuration is suitable. A new instance will be added to the InnoDB cluster. Depending on the amount of data on the cluster this might take from a few seconds to several hours. Adding instance to the cluster... Monitoring recovery process of the new cluster member. Press ^C to stop monitoring and let it continue in background. Clone based state recovery is now in progress. NOTE: A server restart is expected to happen as part of the clone process. If the server does not support the RESTART command or does not come back after a while, you may need to manually start it back. * Waiting for clone to finish... NOTE: ic-2:3306 is being cloned from ic-1:3306 ** Stage DROP DATA: Completed ** Clone Transfer FILE COPY ############################################################ 100% Completed PAGE COPY ############################################################ 100% Completed REDO COPY ############################################################ 100% Completed NOTE: ic-2:3306 is shutting down... * Waiting for server restart... ready * ic-2:3306 has restarted, waiting for clone to finish... ** Stage RESTART: Completed * Clone process has finished: 2.18 GB transferred in 7 sec (311.26 MB/s) State recovery already finished for 'ic-2:3306' The instance 'ic-2:3306' was successfully added to the cluster.The warnings about server restart should be observed, you might have to manually restart an instance. See Section 13.7.8.8, “RESTART Syntax”.
When you use incremental recovery to recover an instance from the cluster, the output looks like:
Incremental distributed state recovery is now in progress. * Waiting for incremental recovery to finish... NOTE: 'ic-2:3306' is being recovered from 'ic-1:3306' * Distributed recovery has finished
To cancel the monitoring of the recovery phase, issue
CONTROL+C. This stops the monitoring but the
recovery process continues in the background. The
waitRecovery integer option can be used
with the
Cluster.addInstance()
0: do not wait and let the recovery process finish in the background;
1: wait for the recovery process to finish;
2: wait for the recovery process to finish; and show detailed static progress information;
3: wait for the recovery process to finish; and show detailed dynamic progress information (progress bars);
By default, if the standard output which MySQL Shell is
running on refers to a terminal, the
waitRecovery option defaults to 3.
Otherwise, it defaults to 2. See
Monitoring Recovery Operations.
To verify the instance has been added, use the cluster
instance's status() function. For
example this is the status output of a sandbox cluster after
adding a second instance:
mysql-js> cluster.status()
{
"clusterName": "testCluster",
"defaultReplicaSet": {
"name": "default",
"primary": "ic-1:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures.",
"topology": {
"ic-1:3306": {
"address": "ic-1:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"ic-2:3306": {
"address": "ic-2:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
},
"groupInformationSourceMember": "mysql://ic@ic-1:3306"
}
How you proceed depends on whether the instance is local or
remote to the instance MySQL Shell is running on, and
whether the instance supports persisting configuration changes
automatically, see
Persisting Settings. If
the instance supports persisting configuration changes
automatically, you do not need to persist the settings
manually and can either add more instances or continue to the
next step. If the instance does not support persisting
configuration changes automatically, you have to configure the
instance locally. See
Configuring Instances with
dba.configureLocalInstance(). This is
essential to ensure that instances rejoin the cluster in the
event of leaving the cluster.
If the instance has
super_read_only=ON then you
might need to confirm that AdminAPI can set
super_read_only=OFF. See
Super Read-only and Instances for more
information.
Once you have your cluster deployed you can configure MySQL Router to provide high availability, see Section 21.3, “Using MySQL Router with InnoDB Cluster”.
In MySQL 8.0.17, InnoDB cluster integrates the MySQL Clone plugin to provide automatic provisioning of joining instances. The process of retrieving the cluster's data so that the instance can synchronize with the cluster is called distributed recovery. When an instance needs to recover a cluster's transactions we distinguish between the donor, which is the cluster instance that provides the data, and the receiver, which is the instance that receives the data from the donor. In previous versions, Group Replication provided only asynchronous replication to recover the transactions required for the joining instance to synchronize with the cluster so that it could join the cluster. For a cluster with a large amount of previously processed transactions it could take a long time for the new instance to recover all of the transactions before being able to join the cluster. Or a cluster which had purged GTIDs, for example as part of regular maintenance, could be missing some of the transactions required to recover the new instance. In such cases the only alternative was to manually provision the instance using tools such as MySQL Enterprise Backup, as shown in Section 18.4.6, “Using MySQL Enterprise Backup with Group Replication”.
MySQL Clone provides an alternative way for an instance to recover the transactions required to synchronize with a cluster. Instead of relying on asynchronous replication to recover the transactions, MySQL Clone takes a snapshot of the data on the donor instance and then transfers the snapshot to the receiver.
All previous data in the receiver is destroyed during a clone operation. All MySQL settings not stored in tables are however maintained.
Once a clone operation has transferred the snapshot to the receiver, if the cluster has processed transactions while the snapshot was being transferred, asynchronous replication is used to recover any required data for the receiver to be synchronized with the cluster. This can be much more efficient than the instance recovering all of the transactions using asynchronous replication, and avoids any issues caused by purged GTIDs, enabling you to quickly provision new instances for InnoDB cluster. For more information, see Section 5.6.7, “The Clone Plugin” and Section 18.4.3.1, “Cloning for Distributed Recovery”
In contrast to using MySQL Clone, incremental recovery is the process where an instance joining a cluster uses only asynchronous replication to recover an instance from the cluster. When an InnoDB cluster is configured to use MySQL Clone, instances which join the cluster use either MySQL Clone or incremental recovery to recover the cluster's transactions. By default, the cluster automatically chooses the most suitable method, but you can optionally configure this behavior, for example to force cloning, which replaces any transactions already processed by the joining instance. When you are using MySQL Shell in interactive mode, the default, if the cluster is not sure it can proceed with recovery it provides an interactive prompt. This section describes the different options you are offered, and the different scenarios which influence which of the options you can choose.
In addition, the output of
Cluster.status()RECOVERING state includes
recovery progress information to enable you to easily monitor
recovery operations, whether they are using MySQL Clone or
incremental recovery. InnoDB cluster provides additional
information about instances using MySQL Clone in the output of
Cluster.status()
A InnoDB cluster that uses MySQL Clone provides the following additional behavior.
From version 8.0.17, by default when a new cluster is
created on an instance where the MySQL Clone plugin is
available then it is automatically installed and the cluster
is configured to support cloning. The InnoDB cluster
recovery accounts are created with the required
BACKUP_ADMIN privilege.
Set the disableClone Boolean option to
true to disable MySQL Clone for the
cluster. In this case a metadata entry is added for this
configuration and the MySQL Clone plugin is uninstalled if
it is installed. You can set the
disableClone option when you issue
dba.createCluster(), or at any time when
the cluster is running using
Cluster.setOption()
MySQL Clone can be used for a joining
instance if the new instance is
running MySQL 8.0.17 or later, and there is at least one
donor in the cluster (included in the
group_replication_group_seeds
list) running MySQL 8.0.17 or later. A cluster using MySQL
Clone follows the behavior documented at
Adding Instances to a Cluster, with the addition
of a possible choice of how to transfer the data required to
recover the instance from the cluster. How
Cluster.addInstance(instance)
Whether MySQL Clone is supported.
Whether incremental recovery is possible or not, which depends on the availability of binary logs. For example, if a donor instance has all binary logs required (
GTID_PURGEDis empty) then incremental recovery is possible. If no cluster instance has all binary logs required then incremental recovery is not possible.Whether incremental recovery is appropriate or not. Even though incremental recovery might be possible, because it has the potential to clash with data already on the instance, the GTID sets on the donor and receiver are checked to make sure that incremental recovery is appropriate. The following are possible results of the comparison:
New: the receiver has an empty
GTID_EXECUTEDGTID setIdentical: the receiver has a GTID set identical to the donor’s GTID set
Recoverable: the receiver has a GTID set that is missing transactions but these can be recovered from the donor
Irrecoverable: the donor has a GTID set that is missing transactions, possibly they have been purged
Diverged: the GTID sets of the donor and receiver have diverged
When the result of the comparison is determined to be Identical or Recoverable, incremental recovery is considered appropriate. When the result of the comparison is determined to be Irrecoverable or Diverged, incremental recovery is not considered appropriate.
For an instance considered New, incremental recovery cannot be considered appropriate because it is impossible to determine if the binary logs have been purged, or even if the
GTID_PURGEDandGTID_EXECUTEDvariables were reset. Alternatively, it could be that the server had already processed transactions before binary logs and GTIDs were enabled. Therefore in interactive mode, you have to confirm that you want to use incremental recovery.The state of the
gtidSetIsCompleteoption. If you are sure a cluster has been created with a complete GTID set, and therefore instances with empty GTID sets can be added to it without extra confirmations, set the cluster levelgtidSetIsCompleteBoolean option totrue.WarningSetting the
gtidSetIsCompleteoption totruemeans that joining servers are recovered regardless of any data they contain, use with caution. If you try to add an instance which has applied transactions you risk data corruption.
The combination of these factors influence how instances
join the cluster when you issue
Cluster.addInstance()recoveryMethod option is set to
auto by default, which means that in
MySQL Shell's interactive mode, the cluster selects the
best way to recover the instance from the cluster, and the
prompts advise you how to proceed. In other words the
cluster recommends using MySQL Clone or incremental recovery
based on the best approach and what the server supports. If
you are not using interactive mode and are scripting
MySQL Shell, you must set
recoveryMethod to the type of recovery
you want to use - either clone or
incremental. This section explains the
different possible scenarios.
When you are using MySQL Shell in interactive mode, the main prompt with all of the possible options for adding the instance is:
Please select a recovery method [C]lone/[I]ncremental recovery/[A]bort (default Clone):
Depending on the factors mentioned, you might not be offered all of these options. The scenarios described later in this section explain which options you are offered. The options offered by this prompt are:
Clone: choose this option to clone the donor to the instance which you are adding to the cluster, deleting any transactions the instance contains. The MySQL Clone plugin is automatically installed. The InnoDB cluster recovery accounts are created with the required
BACKUP_ADMINprivilege. Assuming you are adding an instance which is either empty (has not processed any transactions) or which contains transactions you do not want to retain, select the Clone option. The cluster then uses MySQL Clone to completely overwrite the joining instance with a snapshot from an donor cluster member. To use this method by default and disable this prompt, set the cluster'srecoveryMethodoption toclone.Incremental recovery choose this option to use incremental recovery to recover all transactions processed by the cluster to the joining instance using asynchronous replication. Incremental recovery is appropriate if you are sure all updates ever processed by the cluster were done with GTIDs enabled, there are no purged transactions and the new instance contains the same GTID set as the cluster or a subset of it. To use this method by default, set the
recoveryMethodoption toincremental.
The combination of factors mentioned influences which of these options is available at the prompt as follows:
If the
group_replication_clone_threshold
system variable has been manually changed outside of
AdminAPI, then the cluster might decide to use
Clone recovery instead of following these scenarios.
In a scenario where
incremental recovery is possible
incremental recovery is not appropriate
Clone is supported
you can choose between any of the options. It is recommended that you use MySQL Clone, the default.
In a scenario where
incremental recovery is possible
incremental recovery is appropriate
you are not provided with the prompt, and incremental recovery is used.
In a scenario where
incremental recovery is possible
incremental recovery is not appropriate
Clone is not supported or is disabled
you cannot use MySQL Clone to add the instance to the cluster. You are provided with the prompt, and the recommended option is to proceed with incremental recovery.
In a scenario where
incremental recovery is not possible
Clone is not supported or is disabled
you cannot add the instance to the cluster and an ERROR: The target instance must be either cloned or fully provisioned before it can be added to the target cluster. Cluster.addInstance: Instance provisioning required (RuntimeError) is shown. This could be the result of binary logs being purged from all cluster instances. It is recommended to use MySQL Clone, by either upgrading the cluster or setting the
disableCloneoption tofalse.In a scenario where
incremental recovery is not possible
Clone is supported
you can only use MySQL Clone to add the instance to the cluster. This could be the result of the cluster missing binary logs, for example when they have been purged.
Once you select an option from the prompt, by default the progress of the instance recovering the transactions from the cluster is displayed. This monitoring enables you to check the recovery phase is working and also how long it should take for the instance to join the cluster and come online. To cancel the monitoring of the recovery phase, issue CONTROL+C.
When the
Cluster.checkInstanceState()disableClone is
false) the operation provides a warning
that the Clone can be used. For example:
The cluster transactions cannot be recovered on the instance, however,
Clone is available and can be used when adding it to a cluster.
{
"reason": "all_purged",
"state": "warning"
}
Similarly, on an instance where Clone is either not available or has been disabled and the binary logs are not available, for example because they were purged, then the output includes:
The cluster transactions cannot be recovered on the instance.
{
"reason": "all_purged",
"state": "warning"
}
This section explains how to set up a sandbox InnoDB cluster deployment. You create and administer your InnoDB clusters using MySQL Shell with the included AdminAPI. This section assumes familiarity with MySQL Shell, see MySQL Shell 8.0 (part of MySQL 8.0) for further information.
Initially deploying and using local sandbox instances of MySQL is a good way to start your exploration of InnoDB cluster. You can fully test out InnoDB cluster locally, prior to deployment on your production servers. MySQL Shell has built-in functionality for creating sandbox instances that are correctly configured to work with Group Replication in a locally deployed scenario.
Sandbox instances are only suitable for deploying and running on your local machine for testing purposes. In a production environment the MySQL Server instances are deployed to various host machines on the network. See Section 21.2.4, “Production Deployment of InnoDB Cluster” for more information.
This tutorial shows how to use MySQL Shell to create an InnoDB cluster consisting of three MySQL server instances.
MySQL Shell includes the AdminAPI that adds the
dba global variable, which provides
functions for administration of sandbox instances. In this
example setup, you create three sandbox instances using
dba.deploySandboxInstance().
Start MySQL Shell from a command prompt by issuing the command:
shell> mysqlsh
MySQL Shell provides two scripting language modes,
JavaScript and Python, in addition to a native SQL mode.
Throughout this guide MySQL Shell is used primarily in
JavaScript mode
. When MySQL Shell starts it is in JavaScript mode by
default. Switch modes by issuing \js for
JavaScript mode, \py for Python mode, and
\sql for SQL mode. Ensure you are in
JavaScript mode by issuing the \js command,
then execute:
mysql-js> dba.deploySandboxInstance(3310)
Terminating commands with a semi-colon is not required in JavaScript and Python modes.
The argument passed to
deploySandboxInstance() is the TCP port
number where the MySQL Server instance listens for
connections. By default the sandbox is created in a directory
named
$HOME/mysql-sandboxes/
on Unix systems. For Microsoft Windows systems the directory
is
port%userprofile%\MySQL\mysql-sandboxes\.
port
The root user's password for the instance is prompted for.
Each instance has its own password. Defining the same password for all sandboxes in this tutorial makes it easier, but remember to use different passwords for each instance in production deployments.
To deploy further sandbox server instances, repeat the steps followed for the sandbox instance at port 3310, choosing different port numbers. For each additional sandbox instance issue:
mysql-js> dba.deploySandboxInstance(port_number)
To follow this tutorial, use port numbers 3310, 3320 and 3330 for the three sandbox server instances. Issue:
mysql-js>dba.deploySandboxInstance(mysql-js>3320)dba.deploySandboxInstance(3330)
The next step is to create the InnoDB cluster while connected to the seed MySQL Server instance. The seed instance contains the data that you want to replicate to the other instances. In this example the sandbox instances are blank, therefore we can choose any instance.
Connect MySQL Shell to the seed instance, in this case the one at port 3310:
mysql-js> \connect root@localhost:3310
The \connect MySQL Shell command is a
shortcut for the shell.connect() method:
mysql-js> shell.connect('root@localhost:3310')
Once you have connected, AdminAPI can write to the local instance's option file. This is different to working with a production deployment, where you would need to connect to the remote instance and run the MySQL Shell application locally on the instance before AdminAPI can write to the instance's option file.
Use the dba.createCluster() method to
create the InnoDB cluster with the currently connected
instance as the seed:
mysql-js> var cluster = dba.createCluster('testCluster')
The createCluster() method deploys the
InnoDB cluster metadata to the selected instance, and adds
the instance you are currently connected to as the seed
instance. The createCluster() method
returns the created cluster, in the example above this is
assigned to the cluster variable. The
parameter passed to the createCluster()
method is a symbolic name given to this InnoDB cluster, in
this case testCluster.
If the instance has
super_read_only=ON then you
might need to confirm that AdminAPI can set
super_read_only=OFF. See
Super Read-only and Instances for more
information.
The next step is to add more instances to the InnoDB cluster. Any transactions that were executed by the seed instance are re-executed by each secondary instance as it is added. This tutorial uses the sandbox instances that were created earlier at ports 3320 and 3330.
The seed instance in this example was recently created, so it is nearly empty. Therefore, there is little data that needs to be replicated from the seed instance to the secondary instances. In a production environment, where you have an existing database on the seed instance, you could use a tool such as MySQL Enterprise Backup to ensure that the secondaries have matching data before replication starts. This avoids the possibility of lengthy delays while data replicates from the primary to the secondaries. See Section 18.4.6, “Using MySQL Enterprise Backup with Group Replication”.
Add the second instance to the InnoDB cluster:
mysql-js> cluster.addInstance('root@localhost:3320')
The root user's password is prompted for.
Add the third instance:
mysql-js> cluster.addInstance('root@localhost:3330')
The root user's password is prompted for.
At this point you have created a cluster with three instances: a primary, and two secondaries.
You can only specify localhost in
addInstance() if the instance is a
sandbox instance. This also applies to the implicit
addInstance() after issuing
createCluster().
Once the sandbox instances have been added to the cluster, the
configuration required for InnoDB cluster must be persisted
to each of the instance's option files. How you proceed
depends on whether the instance supports persisting
configuration changes automatically, see
Persisting Settings.
When the MySQL instance which you are using supports
persisting configuration changes automatically, adding the
instance automatically configures the instance. When the MySQL
instance which you are using does not support persisting
configuration changes automatically, you have to configure the
instance locally. See
Configuring Instances with
dba.configureLocalInstance().
To check the cluster has been created, use the cluster
instance's status() function. See
Checking a cluster's Status with
Cluster.status()
Once you have your cluster deployed you can configure MySQL Router to provide high availability, see Section 21.3, “Using MySQL Router with InnoDB Cluster”.
If you have an existing deployment of Group Replication and you
want to use it to create a cluster, pass the
adoptFromGR option to the
dba.createCluster() function. The created
InnoDB cluster matches whether the replication group is
running as single-primary or multi-primary.
To adopt an existing Group Replication group, connect to a group
member using MySQL Shell. In the following example a
single-primary group is adopted. We connect to
gr-member-2, a secondary instance, while
gr-member-1 is functioning as the group's
primary. Create a cluster using
dba.createCluster(), passing in the
adoptFromGR option. For example:
mysql-js> var cluster = dba.createCluster('prodCluster', {adoptFromGR: true});
A new InnoDB cluster will be created on instance 'root@gr-member-2:3306'.
Creating InnoDB cluster 'prodCluster' on 'root@gr-member-2:3306'...
Adding Seed Instance...
Cluster successfully created. Use cluster.addInstance() to add MySQL instances.
At least 3 instances are needed for the cluster to be able to withstand up to
one server failure.
If the instance has
super_read_only=ON then you
might need to confirm that AdminAPI can set
super_read_only=OFF. See
Super Read-only and Instances for more
information.
The new cluster matches the mode of the group. If the adopted group was running in single-primary mode then a single-primary cluster is created. If the adopted group was running in multi-primary mode then a multi-primary cluster is created.
This section describes how to use MySQL Router with InnoDB cluster
to achieve high availability. Regardless of whether you have
deployed a sandbox or production cluster, MySQL Router can configure
itself based on the InnoDB cluster's metadata using the
--bootstrap option. This
configures MySQL Router automatically to route connections to the
cluster's server instances. Client applications connect to
the ports MySQL Router provides, without any need to be aware of the
InnoDB cluster topology. In the event of a unexpected failure,
the InnoDB cluster adjusts itself automatically and MySQL Router
detects the change. This removes the need for your client
application to handle failover. For more information, see
Routing for MySQL InnoDB cluster.
Do not attempt to configure MySQL Router manually to redirect to the
ports of an InnoDB cluster. Always use the
--bootstrap option as this
ensures that MySQL Router takes its configuration from the
InnoDB cluster's metadata. See
Cluster Metadata and State.
The recommended deployment of MySQL Router is on the same host as the application. When using a sandbox deployment, everything is running on a single host, therefore you deploy MySQL Router to the same host. When using a production deployment, we recommend deploying one MySQL Router instance to each machine used to host one of your client applications. It is also possible to deploy MySQL Router to a common machine through which your application instances connect.
Assuming MySQL Router is already installed (see
Installing MySQL Router), use the
--bootstrap option to provide
the location of a server instance that belongs to the
InnoDB cluster. MySQL Router uses the included metadata cache plugin
to retrieve the InnoDB cluster's metadata, consisting of a
list of server instance addresses which make up the
InnoDB cluster and their role in the cluster. You pass the
URI-like connection string of the server that MySQL Router should
retrieve the InnoDB cluster metadata from. For example:
shell> mysqlrouter --bootstrap ic@ic-1:3306 --user=mysqlrouter
You are prompted for the instance password and encryption key for
MySQL Router to use. This encryption key is used to encrypt the
instance password used by MySQL Router to connect to the cluster. The
ports you can use to connect to the InnoDB cluster are also
displayed. The MySQL Router bootstrap process creates a
mysqlrouter.conf file, with the settings
based on the cluster metadata retrieved from the address passed to
the --bootstrap option, in the
above example ic@ic-1:3306. Based on the
InnoDB cluster metadata retrieved, MySQL Router automatically
configures the mysqlrouter.conf file,
including a metadata_cache section with
bootstrap_server_addresses
containing the addresses for all server instances in the cluster.
For example:
[metadata_cache:prodCluster] router_id=1 bootstrap_server_addresses=mysql://ic@ic-1:3306,mysql://ic@ic-2:3306,mysql://ic@ic-3:3306 user=mysql_router1_jy95yozko3k2 metadata_cluster=prodCluster ttl=300
When you change the topology of a cluster by adding another
server instance after you have bootstrapped MySQL Router, you need
to update
bootstrap_server_addresses
based on the updated metadata. Either restart MySQL Router using the
--bootstrap option, or
manually edit the
bootstrap_server_addresses
section of the mysqlrouter.conf file and
restart MySQL Router.
The generated MySQL Router configuration creates TCP ports which you use to connect to the cluster. Ports for communicating with the cluster using both Classic MySQL protocol and X Protocol are created. To use X Protocol the server instances must have X Plugin installed and configured. For a sandbox deployment, instances have X Plugin set up automatically. For a production deployment, if you want to use X Protocol you need to install and configure X Plugin on each instance, see Setting Up MySQL as a Document Store. The default available TCP ports are:
6446- for Classic MySQL protocol read-write sessions, which MySQL Router redirects incoming connections to primary server instances.6447- for Classic MySQL protocol read-only sessions, which MySQL Router redirects incoming connections to one of the secondary server instances.64460- for X Protocol read-write sessions, which MySQL Router redirects incoming connections to primary server instances.64470- for X Protocol read-only sessions, which MySQL Router redirects incoming connections to one of the secondary server instances.
Depending on your MySQL Router configuration the port numbers might be
different to the above. For example if you use the
--conf-base-port option, or
the
group_replication_single_primary_mode
variable. The exact ports are listed when you start MySQL Router.
The way incoming connections are redirected depends on the type of
cluster being used. When using a single-primary cluster, by
default MySQL Router publishes a X Protocol and a classic
protocol port, which clients connect to for read-write sessions
and which are redirected to the cluster's single primary. With a
multi-primary cluster read-write sessions are redirected to one of
the primary instances in a round-robin fashion. For example, this
means that the first connection to port 6446 would be redirected
to the ic-1 instance, the second connection to port 6446 would be
redirected to the ic-2 instance, and so on. For incoming read-only
connections MySQL Router redirects connections to one of the secondary
instances, also in a round-robin fashion. To modify this behavior
see the routing_strategy
option.
Once bootstrapped and configured, start MySQL Router. If you used a
system wide install with the
--bootstrap option then issue:
shell> mysqlrouter &
If you installed MySQL Router to a directory using the
--directory option, use the
start.sh script found in the directory you
installed to. Alternatively set up a service to start MySQL Router
automatically when the system boots, see
Starting MySQL Router. You can now
connect a MySQL client, such as MySQL Shell to one of the
incoming MySQL Router ports as described above and see how the client
gets transparently connected to one of the InnoDB cluster
instances.
shell> mysqlsh --uri root@localhost:6442
To verify which instance you are actually connected to, simply
issue an SQL query against the
port status variable.
mysql-js>\sqlSwitching to SQL mode... Commands end with ; mysql-sql>select @@port;+--------+ | @@port | +--------+ | 3310 | +--------+
To test if high availability works, simulate an unexpected halt by killing an instance. The cluster detects the fact that the instance left the cluster and reconfigures itself. Exactly how the cluster reconfigures itself depends on whether you are using a single-primary or multi-primary cluster, and the role the instance serves within the cluster.
In single-primary mode:
If the current primary leaves the cluster, one of the secondary instances is elected as the new primary, with instances prioritized by the lowest
server_uuid. MySQL Router redirects read-write connections to the newly elected primary.If a current secondary leaves the cluster, MySQL Router stops redirecting read-only connections to the instance.
For more information see Section 18.1.3.1, “Single-Primary Mode”.
In multi-primary mode:
If a current "R/W" instance leaves the cluster, MySQL Router redirects read-write connections to other primaries. If the instance which left was the last primary in the cluster then the cluster is completely gone and you cannot connect to any MySQL Router port.
For more information see Section 18.1.3.2, “Multi-Primary Mode”.
There are various ways to simulate an instance leaving a
cluster, for example you can forcibly stop the MySQL server on
an instance, or use the AdminAPI
dba.killSandboxInstance() if testing a
sandbox deployment. In this example assume there is a
single-primary sandbox cluster deployment with three server
instances and the instance listening at port 3310 is the current
primary. Simulate the instance leaving the cluster unexpectedly:
mysql-js> dba.killSandboxInstance(3310)
The cluster detects the change and elects a new primary
automatically. Assuming your session is connected to port 6446,
the default read-write classic MySQL protocol port, MySQL Router
should detect the change to the cluster's topology and redirect
your session to the newly elected primary. To verify this,
switch to SQL mode in MySQL Shell using the
\sql command and select the instance's
port variable to check which
instance your session has been redirected to. Notice that the
first SELECT statement fails as
the connection to the original primary was lost. This means the
current session has been closed, MySQL Shell automatically
reconnects for you and when you issue the command again the new
port is confirmed.
mysql-js>\sqlSwitching to SQL mode... Commands end with ; mysql-sql>SELECT @@port;ERROR: 2013 (HY000): Lost connection to MySQL server during query The global session got disconnected. Attempting to reconnect to 'root@localhost:6446'... The global session was successfully reconnected. mysql-sql>SELECT @@port;+--------+ | @@port | +--------+ | 3330 | +--------+ 1 row in set (0.00 sec)
In this example, the instance at port 3330 has been elected as the new primary. This shows that the InnoDB cluster provided us with automatic failover, that MySQL Router has automatically reconnected us to the new primary instance, and that we have high availability.
When MySQL Router is bootstrapped against a cluster, it records the server instance's addresses in its configuration file. If any additional instances are added to the cluster after bootstrapping the MySQL Router, they are not automatically detected and therefore are not used for connection routing.
To ensure that newly added instances are routed to correctly you
must bootstrap MySQL Router against the cluster to read the updated
metadata. This means that you must restart MySQL Router and include
the --bootstrap option.
This section explains how to work with InnoDB cluster, and how to handle common administration tasks.
Before creating a production deployment from server instances
you need to check that MySQL on each instance is correctly
configured. In addition to
dba.configureInstance(), which checks the
configuration as part of configuring an instance, you can use
the dba.checkInstanceConfiguration()
function. This ensures that the instance satisfies the
Section 21.2.2, “InnoDB Cluster Requirements” without
changing any configuration on the instance. This does not check
any data that is on the instance, see
Checking Instance State for more information. The
following demonstrates issuing this in a running MySQL Shell:
mysql-js> dba.checkInstanceConfiguration('ic@ic-1:3306')
Please provide the password for 'ic@ic-1:3306': ***
Validating MySQL instance at ic-1:3306 for use in an InnoDB cluster...
This instance reports its own address as ic-1
Clients and other cluster members will communicate with it through this address by default.
If this is not correct, the report_host MySQL system variable should be changed.
Checking whether existing tables comply with Group Replication requirements...
No incompatible tables detected
Checking instance configuration...
Some configuration options need to be fixed:
+--------------------------+---------------+----------------+--------------------------------------------------+
| Variable | Current Value | Required Value | Note |
+--------------------------+---------------+----------------+--------------------------------------------------+
| binlog_checksum | CRC32 | NONE | Update the server variable |
| enforce_gtid_consistency | OFF | ON | Update read-only variable and restart the server |
| gtid_mode | OFF | ON | Update read-only variable and restart the server |
| server_id | 1 | | Update read-only variable and restart the server |
+--------------------------+---------------+----------------+--------------------------------------------------+
Please use the dba.configureInstance() command to repair these issues.
{
"config_errors": [
{
"action": "server_update",
"current": "CRC32",
"option": "binlog_checksum",
"required": "NONE"
},
{
"action": "restart",
"current": "OFF",
"option": "enforce_gtid_consistency",
"required": "ON"
},
{
"action": "restart",
"current": "OFF",
"option": "gtid_mode",
"required": "ON"
},
{
"action": "restart",
"current": "1",
"option": "server_id",
"required": ""
}
],
"status": "error"
}
Repeat this process for each server instance that you plan to
use as part of your cluster. The report generated after running
dba.checkInstanceConfiguration() provides
information about any configuration changes required before you
can proceed. The action field in the
config_error section of the report tells you
whether MySQL on the instance requires a restart to detect any
change made to the configuration file.
Instances which do not support persisting configuration changes
automatically (see
Persisting Settings)
require you to connect to the server, run MySQL Shell, connect
to the instance locally and issue
dba.configureLocalInstance(). This enables
MySQL Shell to modify the instance's option file after running
the following commands against a remote instance:
dba.configureInstance()dba.createCluster()Cluster.addInstance()Cluster.removeInstance()Cluster.rejoinInstance()
Failing to persist configuration changes to an instance's option file can result in the instance not rejoining the cluster after the next restart.
The recommended method is to log in to the remote machine, for
example using SSH, run MySQL Shell as the root user and then
connect to the local MySQL server. For example, use the
--uri option to connect to the
local instance:
shell> sudo -i mysqlsh --uri=instance
Alternatively use the \connect command to log
in to the local instance. Then issue
dba.configureInstance(,
where instance)instance is the connection
information to the local instance, to persist any changes made
to the local instance's option file.
mysql-js> dba.configureLocalInstance('ic@ic-2:3306')
Repeat this process for each instance in the cluster which does not support persisting configuration changes automatically. For example if you add 2 instances to a cluster which do not support persisting configuration changes automatically, you must connect to each server and persist the configuration changes required for InnoDB cluster before the instance restarts. Similarly if you modify the cluster structure, for example changing the number of instances, you need to repeat this process for each server instance to update the InnoDB cluster metadata accordingly for each instance in the cluster.
When you create a cluster using
dba.createCluster(), the operation returns a
Cluster object which can be assigned to a variable. You use this
object to work with the cluster, for example to add instances or
check the cluster's status. If you want to retrieve a cluster
again at a later date, for example after restarting
MySQL Shell, use the
dba.getCluster([
function. For example:
name],[options])
mysql-js> var cluster1 = dba.getCluster()
If you do not specify a cluster name
then the default cluster is returned.
By default MySQL Shell attempts to connect to the primary
instance of the cluster when you use
dba.getCluster(). Set the
connectToPrimary option to configure this
behavior. If connectToPrimary is
true and the active global MySQL Shell
session is not to a primary instance, the cluster is queried for
the primary member and the cluster object connects to it. If
there is no quorum in the cluster, the operation fails. If
connectToPrimary is false,
the cluster object uses the active session, in other words the
same instance as the MySQL Shell's current global session. If
connectToPrimary is not specified,
MySQL Shell treats connectToPrimary as
true, and falls back to
connectToPrimary being
false.
To force connecting to a secondary when getting a cluster,
establish a connection to the secondary member of the cluster
and use the connectToPrimary option by
issuing:
mysql-js>shell.connect(secondary_member)mysql-js>var cluster1 = dba.getCluster(testCluster, {connectToPrimary:false})
Remember that secondary instances have
super_read_only=ON, so you
cannot write changes to them.
To get information about the structure of the InnoDB cluster
itself, use the
Cluster.describe()
mysql-js> cluster.describe();
{
"clusterName": "testCluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "ic-1:3306",
"label": "ic-1:3306",
"role": "HA"
},
{
"address": "ic-2:3306",
"label": "ic-2:3306",
"role": "HA"
},
{
"address": "ic-3:3306",
"label": "ic-3:3306",
"role": "HA"
}
]
}
}
The output from this function shows the structure of the
InnoDB cluster including all of its configuration information,
and so on. The address, label and role values match those
described at Checking a cluster's Status with
Cluster.status()
Cluster objects provide the status() method
that enables you to check how a cluster is running. Before you
can check the status of the InnoDB cluster, you need to get a
reference to the InnoDB cluster object by connecting to any of
its instances. However, if you want to make changes to the
configuration of the cluster, you must connect to a "R/W"
instance. Issuing status() retrieves the
status of the cluster based on the view of the cluster which the
server instance you are connected to is aware of and outputs a
status report.
The instance's state in the cluster directly influences the
information provided in the status report. Therefore ensure
the instance you are connected to has a status of
ONLINE.
For information about how the InnoDB cluster is running, use
the cluster's status() method:
mysql-js>var cluster = dba.getCluster()mysql-js>cluster.status(){ "clusterName": "testcluster", "defaultReplicaSet": { "name": "default", "primary": "ic-1:3306", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": { "ic-1:3306": { "address": "ic-1:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "ic-2:3306": { "address": "ic-2:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" }, "ic-3:3306": { "address": "ic-3:3306", "mode": "R/O", "readReplicas": {}, "role": "HA", "status": "ONLINE" } } }, "groupInformationSourceMember": "mysql://ic@ic-1:3306" }
The output of
Cluster.status()
clusterName: name assigned to this cluster duringdba.createCluster().defaultReplicaSet: the server instances which belong to an InnoDB cluster and contain the data set.primary: displayed when the cluster is operating in single-primary mode only. Shows the address of the current primary instance. If this field is not displayed, the cluster is operating in multi-primary mode.ssl: whether secure connections are used by the cluster or not. Shows values ofREQUIREDorDISABLED, depending on how thememberSslModeoption was configured during eithercreateCluster()oraddInstance(). The value returned by this parameter corresponds to the value of thegroup_replication_ssl_modeserver variable on the instance. See Securing your Cluster.status: The status of this element of the cluster. For the overall cluster this describes the high availability provided by this cluster. The status is one of the following:ONLINE: The instance is online and participating in the cluster.OFFLINE: The instance has lost connection to the other instances.RECOVERING: The instance is attempting to synchronize with the cluster by retrieving transactions it needs before it can become anONLINEmember.UNREACHABLE: The instance has lost communication with the cluster.ERROR: The instance has encountered an error during the recovery phase or while applying a transaction.ImportantOnce an instance enters
ERRORstate, thesuper_read_onlyoption is set toON. To leave theERRORstate you must manually configure the instance withsuper_read_only=OFF.(MISSING): The state of an instance which is part of the configured cluster, but is currently unavailable.NoteThe
MISSINGstate is specific to InnoDB cluster, it is not a state generated by Group Replication. MySQL Shell uses this state to indicate instances that are registered in the metadata, but cannot be found in the live cluster view.
topology: The instances which have been added to the cluster.Host name of instance: The host name of an instance, for example localhost:3310.role: what function this instance provides in the cluster. Currently only HA, for high availability.mode: whether the server is read-write ("R/W") or read-only ("R/O"). From version 8.0.17, this is derived from the current state of thesuper_read_onlyvariable on the instance, and whether the cluster has quorum. In previous versions the value of mode was derived from whether the instance was serving as a primary or secondary instance. Usually if the instance is a primary, then the mode is "R/W", and if the instance is a secondary the mode is "R/O". Any instances in a cluster that have no visible quorum are marked as "R/O", regardless of the state of thesuper_read_onlyvariable.groupInformationSourceMember: the internal connection used to get information about the cluster, shown as a URI-like connection string. Usually the connection initially used to create the cluster.
To display more information about the cluster use the
extended option. From version 8.0.17, the
extended option supports integer or Boolean
values. To configure the additional information that
Cluster.status({'extended':value})
0: disables the additional information, the default
1: includes information about the Group Replication Protocol Version, Group name, cluster member UUIDs, cluster member roles and states as reported by Group Replication, and the list of fenced system variables
2: includes information about transactions processed by connection and applier
3: includes more detailed statistics about the replication performed by each cluster member.
Setting extended using Boolean values is the
equivalent of setting the integer values 0 and 1. In versions
prior to 8.0.17, the extended option was only
Boolean. Similarly prior versions used the
queryMembers Boolean option to provide more
information about the instances in the cluster, which is the
equivalent of setting extended to 3. The
queryMembers option is deprecated and
scheduled to be removed in a future release.
When you issue
Cluster.status({'extended':1})extended option is set to
true, the output includes:
the following additional attributes for the
defaultReplicaSetobject:GRProtocolVersionis the Group Replication Protocol Version being used in the cluster.TipInnoDB cluster manages the Group Replication Protocol version being used automatically, see InnoDB cluster and Group Replication Protocol for more information.
groupNameis the group's name, a UUID.
the following additional attributes for each object of the
topologyobject:fenceSysVarsa list containing the name of the fenced system variables which are enabled. Currently the fenced system variables considered areread_only,super_read_onlyandoffline_mode.memberIdEach cluster member UUID.memberRolethe Member Role as reported by the Group Replication plugin, see theMEMBER_ROLEcolumn of thereplication_group_memberstable.memberStatethe Member State as reported by the Group Replication plugin, see theMEMBER_STATEcolumn of thereplication_group_memberstable.
To see information about recovery and regular transaction I/O,
applier worker thread statistics and any lags; applier
coordinator statistics, if parallel apply is enabled; error, and
other information from I/O and applier threads issue use the
values 2 and 3. A value of 3 is the equivalent of setting the
deprecated queryMembers option to
true. When you use these values, a connection
to each instance in the cluster is opened so that additional
instance specific statistics can be queried. The exact
statistics that are included in the output depend on the state
and configuration of the instance and the server version. This
information matches that shown in the
replication_group_member_stats
table, see the descriptions of the matching columns for more
information. Instances which are ONLINE have
a transactions section included in the
output. Instances which are RECOVERING have a
recovery section included in the output. When
you set extended to 2, in either case, these
sections can contain the following:
appliedCount: seeCOUNT_TRANSACTIONS_REMOTE_APPLIEDcheckedCount: seeCOUNT_TRANSACTIONS_CHECKEDcommittedAllMembers: seeTRANSACTIONS_COMMITTED_ALL_MEMBERSconflictsDetectedCount: seeCOUNT_CONFLICTS_DETECTEDinApplierQueueCount: seeCOUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUEinQueueCount: seeCOUNT_TRANSACTIONS_IN_QUEUElastConflictFree: seeLAST_CONFLICT_FREE_TRANSACTIONproposedCount: seeCOUNT_TRANSACTIONS_LOCAL_PROPOSEDrollbackCount: seeCOUNT_TRANSACTIONS_LOCAL_ROLLBACK
When you set extended to 3, the
connection section shows information from the
replication_connection_status
table. The connection section can contain the
following:
The currentlyQueueing section has information
about the transactions currently queued:
immediateCommitTimestamp: seeQUEUEING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPimmediateCommitToNowTime: seeQUEUEING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPminusNOW()originalCommitTimestamp: seeQUEUEING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPoriginalCommitToNowTime: seeQUEUEING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPminusNOW()startTimestamp: seeQUEUEING_TRANSACTION_START_QUEUE_TIMESTAMPtransaction: seeQUEUEING_TRANSACTIONlastHeartbeatTimestamp: seeLAST_HEARTBEAT_TIMESTAMP
The lastQueued section has information about
the most recently queued transaction:
endTimestamp: seeLAST_QUEUED_TRANSACTION_END_QUEUE_TIMESTAMPimmediateCommitTimestamp: seeLAST_QUEUED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPimmediateCommitToEndTime:LAST_QUEUED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPminusNOW()originalCommitTimestamp: seeLAST_QUEUED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPoriginalCommitToEndTime:LAST_QUEUED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPminusNOW()queueTime:LAST_QUEUED_TRANSACTION_END_QUEUE_TIMESTAMPminusLAST_QUEUED_TRANSACTION_START_QUEUE_TIMESTAMPstartTimestamp: seeLAST_QUEUED_TRANSACTION_START_QUEUE_TIMESTAMPtransaction: seeLAST_QUEUED_TRANSACTIONreceivedHeartbeats: seeCOUNT_RECEIVED_HEARTBEATSreceivedTransactionSet: seeRECEIVED_TRANSACTION_SETthreadId: seeTHREAD_ID
Instances which are using a multithreaded slave have a
workers section which contains information
about the worker threads, and matches the information shown by
the
replication_applier_status_by_worker
table.
The lastApplied section shows the following
information about the last transaction applied by the worker:
applyTime: seeLAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMPminusLAST_APPLIED_TRANSACTION_START_APPLY_TIMESTAMPendTimestamp: seeLAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMPimmediateCommitTimestamp: seeLAST_APPLIED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPimmediateCommitToEndTime: seeLAST_APPLIED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPminusNOW()originalCommitTimestamp: seeLAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPoriginalCommitToEndTime: seeLAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPminusNOW()startTimestamp: seeLAST_APPLIED_TRANSACTION_START_APPLY_TIMESTAMPtransaction: seeLAST_APPLIED_TRANSACTION
The currentlyApplying section shows the
following information about the transaction currently being
applied by the worker:
immediateCommitTimestamp: seeAPPLYING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPimmediateCommitToNowTime: seeAPPLYING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPminusNOW()originalCommitTimestamp: seeAPPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPoriginalCommitToNowTime: seeAPPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPminusNOW()startTimestamp: seeAPPLYING_TRANSACTION_START_APPLY_TIMESTAMPtransaction: seeAPPLYING_TRANSACTION
The lastProcessed section has the following
information about the last transaction processed by the worker:
bufferTime:LAST_PROCESSED_TRANSACTION_END_BUFFER_TIMESTAMPminusLAST_PROCESSED_TRANSACTION_START_BUFFER_TIMESTAMPendTimestamp: seeLAST_PROCESSED_TRANSACTION_END_BUFFER_TIMESTAMPimmediateCommitTimestamp: seeLAST_PROCESSED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPimmediateCommitToEndTime:LAST_PROCESSED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPminusLAST_PROCESSED_TRANSACTION_END_BUFFER_TIMESTAMPoriginalCommitTimestamp: seeLAST_PROCESSED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPoriginalCommitToEndTime:LAST_PROCESSED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPminusLAST_PROCESSED_TRANSACTION_END_BUFFER_TIMESTAMPstartTimestamp: seeLAST_PROCESSED_TRANSACTION_START_BUFFER_TIMESTAMPtransaction: seeLAST_PROCESSED_TRANSACTION
If parallel applier workers are enabled, then the number of
objects in the workers array in transactions
or recovery matches the number of configured
workers and an additional coordinator object is included. The
information shown matches the information in the
replication_applier_status_by_coordinator
table. The object can contain:
The currentlyProcessing section has the
following information about the transaction being processed by
the worker:
immediateCommitTimestamp: seePROCESSING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPimmediateCommitToNowTime:PROCESSING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMPminusNOW()originalCommitTimestamp: seePROCESSING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPoriginalCommitToNowTime:PROCESSING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMPminusNOW()startTimestamp: seePROCESSING_TRANSACTION_START_BUFFER_TIMESTAMPtransaction: seePROCESSING_TRANSACTION
worker objects have the following information
if an error was detected in the
replication_applier_status_by_worker
table:
lastErrno: seeLAST_ERROR_NUMBERlastError: seeLAST_ERROR_MESSAGElastErrorTimestamp: seeLAST_ERROR_TIMESTAMP
connection objects have the following
information if an error was detected in the
replication_connection_status
table:
lastErrno: seeLAST_ERROR_NUMBERlastError: seeLAST_ERROR_MESSAGElastErrorTimestamp: seeLAST_ERROR_TIMESTAMP
coordinator objects have the following
information if an error was detected in the
replication_applier_status_by_coordinator
table:
lastErrno: seeLAST_ERROR_NUMBERlastError: seeLAST_ERROR_MESSAGElastErrorTimestamp: seeLAST_ERROR_TIMESTAMP
The output of
Cluster.status()RECOVERING state. Information is
shown for instances recovering using either MySQL Clone, or
incremental recovery. Monitor these fields:
The
recoveryStatusTextfield includes information about the type of recovery being used. When MySQL Clone is working the field shows “Cloning in progress”. When incremental recovery is working the field shows “Distributed recovery in progress”.When MySQL Clone is being used, the
recoveryfield includes a dictionary with the following fields:cloneStartTime: The timestamp of the start of the clone processcloneState: The state of the clone progresscurrentStage: The current stage which the clone process has reachedcurrentStageProgress: The current stage progress as a percentage of completioncurrentStageState: The current stage state
Example
Cluster.status()... "recovery": { "cloneStartTime": "2019-07-15 12:50:22.730", "cloneState": "In Progress", "currentStage": "FILE COPY", "currentStageProgress": 61.726837675213865, "currentStageState": "In Progress" }, "recoveryStatusText": "Cloning in progress", ...When incremental recovery is being used, the
recoveryfield includes a dictionary with the following field:state: The state of thegroup_replication_recoverychannel
Example output
Cluster.status()... "recovery": { "state": "ON" }, ...
From MySQL 8.0.16, Group Replication has the concept of a communication protocol for the group, see Section 18.4.1.4, “Setting a Group's Communication Protocol Version” for background information. The Group Replication communication protocol version usually has to be managed explicitly, and set to accommodate the oldest MySQL Server version that you want the group to support. However, InnoDB cluster automatically and transparently manages the communication protocol versions of its members, whenever the cluster topology is changed using AdminAPI operations. A cluster always uses the most recent communication protocol version that is supported by all the instances that are currently part of the cluster or joining it.
When an instance is added to, removed from, or rejoins the cluster, or a rescan or reboot operation is carried out on the cluster, the communication protocol version is automatically set to a version supported by the instance that is now at the earliest MySQL Server version.
When you carry out a rolling upgrade by removing instances from the cluster, upgrading them, and adding them back into the cluster, the communication protocol version is automatically upgraded when the last remaining instance at the old MySQL Server version is removed from the cluster prior to its upgrade.
To see the communication protocol version being used in a
cluster, use the
Cluster.status()extended option enabled.
The communication protocol version is returned in the
GRProtocolVersion field, provided that the
cluster has quorum and no cluster members are unreachable.
The following operations can report information about the MySQL Server version running on the instance:
Cluster.status()Cluster.describe()Cluster.rescan()
The behavior varies depending on the MySQL Server version of the
Cluster object session.
Cluster.status()If either of the following requirements are met, a
versionstring attribute is returned for each instance JSON object of thetopologyobject:The
Clusterobject's current session is version 8.0.11 or later.The
Clusterobject's current session is running a version earlier than version 8.0.11 but theextendedoption is set to 3 (or the deprecatedqueryMembersistrue).
For example on an instance running version 8.0.16:
"topology": { "ic-1:3306": { "address": "ic-1:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE", "version": "8.0.16" }For example on an instance running version 5.7.24:
"topology": { "ic-1:3306": { "address": "ic-1:3306", "mode": "R/W", "readReplicas": {}, "role": "HA", "status": "ONLINE", "version": "5.7.24" }Cluster.describe()If the
Clusterobject's current session is version 8.0.11 or later, aversionstring attribute is returned for each instance JSON object of thetopologyobjectFor example on an instance running version 8.0.16:
"topology": [ { "address": "ic-1:3306", "label": "ic-1:3306", "role": "HA", "version": "8.0.16" } ]Cluster.rescan()If the
Clusterobject's current session is version 8.0.11 or later, and theCluster.rescan()versionstring attribute is returned for each instance JSON object of thenewlyDiscoveredInstanceobject.For example on an instance running version 8.0.16:
"newlyDiscoveredInstances": [ { "host": "ic-4:3306", "member_id": "82a67a06-2ba3-11e9-8cfc-3c6aa7197deb", "name": null, "version": "8.0.16" } ]
Whenever Group Replication stops, the
super_read_only variable is set
to ON to ensure no writes are made to the
instance. When you try to use such an instance with the
following AdminAPI commands you are given the choice to
set super_read_only=OFF on the
instance:
dba.configureInstance()dba.configureLocalInstance()dba.dropMetadataSchema()
When AdminAPI encounters an instance which has
super_read_only=ON, in
interactive mode you are given the choice to set
super_read_only=OFF. For
example:
mysql-js> var myCluster = dba.dropMetadataSchema()
Are you sure you want to remove the Metadata? [y/N]: y
The MySQL instance at 'localhost:3310' currently has the super_read_only system
variable set to protect it from inadvertent updates from applications. You must
first unset it to be able to perform any changes to this instance.
For more information see:
https://dev.mysql.com/doc/refman/en/server-system-variables.html#sysvar_super_read_only.
Do you want to disable super_read_only and continue? [y/N]: y
Metadata Schema successfully removed.
The number of current active sessions to the instance is shown.
You must ensure that no applications can write to the instance
inadvertently. By answering y you confirm
that AdminAPI can write to the instance. If there is
more than one open session to the instance listed, exercise
caution before permitting AdminAPI to set
super_read_only=OFF.
To force the function to set
super_read_only=OFF in a
script, pass the clearReadOnly option set to
true. For example
dba.configureInstance(
instance,
{clearReadOnly: true}).
The recommended way to create a user which can administer an
InnoDB cluster is to use the clusterAdmin
and clusterAdminPassword options with the
dba.configureInstance() or
dba.configureLocalInstance() operations. If
you want to manually configure a user which can administer an
InnoDB cluster that user requires the following privileges,
all with GRANT OPTION:
Global privileges on *.* for
RELOAD,SHUTDOWN,PROCESS,FILE,SELECT,SUPER,REPLICATION SLAVE,REPLICATION CLIENT,CREATE USER.Schema specific privileges for
mysql_innodb_cluster_metadata.*areALTER,ALTER ROUTINE,CREATE,CREATE ROUTINE,CREATE TEMPORARY TABLES,CREATE VIEW,DELETE,DROP,EVENT,EXECUTE,INDEX,INSERT, LOCK TABLES,REFERENCES, SHOW VIEW,TRIGGER,UPDATE; and formysql.*areINSERT,UPDATE,DELETE;
If only read operations are needed, for example to create a user
for monitoring purposes, an account with more restricted
privileges can be used. To give the user
your_user the privileges needed to
monitor InnoDB cluster issue:
GRANT SELECT ON mysql_innodb_cluster_metadata.* TOyour_user@'%'; GRANT SELECT ON performance_schema.global_status TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_applier_configuration TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_applier_status TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_applier_status_by_coordinator TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_applier_status_by_worker TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_connection_configuration TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_connection_status TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_group_member_stats TOyour_user@'%'; GRANT SELECT ON performance_schema.replication_group_members TOyour_user@'%'; GRANT SELECT ON performance_schema.threads TOyour_user@'%'WITH GRANT OPTION;
For more information, see Section 13.7.1, “Account Management Statements”.
Instances running MySQL 8.0.16 and later support the Group
Replication automatic rejoin functionality, which enables you to
configure instances to automatically rejoin the cluster after
being expelled. See
Section 18.6.6, “Responses to Failure Detection and Network Partitioning” for
background information. AdminAPI provides the
autoRejoinTries option to configure the
number of tries instances make to rejoin the cluster after being
expelled. By default instances do not automatically rejoin the
cluster. You can configure the
autoRejoinTries option at either the cluster
level or for an individual instance using the following
commands:
dba.createCluster()Cluster.addInstance()Cluster.setOption()Cluster.setInstanceOption()
The autoRejoinTries option accepts positive
integer values between 0 and 2016 and the default value is 0,
which means that instances do not try to automatically rejoin.
When you are using the automatic rejoin functionality, your
cluster is more tolerant to faults, especially temporary ones
such as unreliable networks. But if quorum has been lost, you
should not expect members to automatically rejoin the cluster,
because majority is required to rejoin instances.
Instances running MySQL version 8.0.12 and later have the
group_replication_exit_state_action
variable, which you can configure using the AdminAPI
exitStateAction option. This controls what
instances do in the event of leaving the cluster unexpectedly.
By default the exitStateAction option is
READ_ONLY, which means that instances which
leave the cluster unexpectedly become read-only. If
exitStateAction is set to
OFFLINE_MODE (available from MySQL 8.0.18),
instances which leave the cluster unexpectedly become read-only
and also enter offline mode, where they disconnect existing
clients and do not accept new connections (except from clients
with administrator privileges). If
exitStateAction is set to
ABORT_SERVER then in the event of leaving the
cluster unexpectedly, the instance shuts down MySQL, and it has
to be started again before it can rejoin the cluster. Note that
when you are using the automatic rejoin functionality, the
action configured by the exitStateAction
option only happens in the event that all attempts to rejoin the
cluster fail.
There is a chance you might connect to an instance and try to configure it using the AdminAPI, but at that moment the instance could be rejoining the cluster. This could happen whenever you use any of these operations:
Cluster.status()dba.getCluster()Cluster.rejoinInstance()Cluster.addInstance()Cluster.removeInstance()Cluster.rescan()Cluster.checkInstanceState()
These operations might provide extra information
while the instance is automatically rejoining the cluster. In
addition, when you are using
Cluster.removeInstance()force:true.
Once a sandbox instance is running, it is possible to change its status at any time using the following:
To stop a sandbox instance use
dba.stopSandboxInstance(. This stops the instance gracefully, unlikeinstance)dba.killSandboxInstance(.instance)To start a sandbox instance use
dba.startSandboxInstance(.instance)To kill a sandbox instance use
dba.killSandboxInstance(. This stops the instance without gracefully stopping it and is useful in simulating unexpected halts.instance)To delete a sandbox instance use
dba.deleteSandboxInstance(. This completely removes the sandbox instance from your file system.instance)
You can remove an instance from a cluster at any time should you
wish to do so. This can be done with the
Cluster.removeInstance(instance)
mysql-js> cluster.removeInstance('root@localhost:3310')
The instance will be removed from the InnoDB cluster. Depending on the instance
being the Seed or not, the Metadata session might become invalid. If so, please
start a new session to the Metadata Storage R/W instance.
Attempting to leave from the Group Replication group...
The instance 'localhost:3310' was successfully removed from the cluster.
You can optionally pass in the interactive
option to control whether you are prompted to confirm the
removal of the instance from the cluster. In interactive mode,
you are prompted to continue with the removal of the instance
(or not) in case it is not reachable. The
cluster.removeInstance()ONLINE,
and the instance itself.
When the instance being removed has transactions which still
need to be applied, AdminAPI waits for up to the number
of seconds configured by the MySQL Shell
dba.gtidWaitTimeout option for transactions
(GTIDs) to be applied. The MySQL Shell
dba.gtidWaitTimeout option has a default
value of 60 seconds, see
Configuring MySQL Shell Options for
information on changing the default. If the timeout value
defined by dba.gtidWaitTimeout is reached
when waiting for transactions to be applied and the
force option is false (or
not defined) then an error is issued and the remove operation is
aborted. If the timeout value defined by
dba.gtidWaitTimeout is reached when waiting
for transactions to be applied and the force
option is set to true then the operation
continues without an error and removes the instance from the
cluster.
The force option should only be used with
Cluster.removeInstance(instance)UNREACHABLE, and do not plan to reuse the
instance with the cluster. Ignoring errors when removing an
instance from the cluster could result in an instance which is
not in synchrony with the cluster, preventing it from
rejoining the cluster at a later time. Only use the
force option when you plan to no longer use
the instance with the cluster, in all other cases you should
always try to recover the instance and only remove it when it
is available and healthy, in other words with the status
ONLINE.
When you create a cluster and add instances to it, values such
as the group name, the local address, and the seed instances are
configured automatically by AdminAPI. These default
values are recommended for most deployments, but advanced users
can override the defaults by passing the following options to
the dba.createCluster() and
Cluster.addInstance()
To customize the name of the replication group created by
InnoDB cluster, pass the groupName option
to the dba.createCluster() command. This sets
the
group_replication_group_name
system variable. The name must be a valid UUID.
To customize the address which an instance provides for
connections from other instances, pass the
localAddress option to the
dba.createCluster() and
cluster.addInstance() commands. Specify the
address in the format
host:portgroup_replication_local_address
system variable on the instance. The address must be accessible
to all instances in the cluster, and must be reserved for
internal cluster communication only. In other words do not use
this address for communication with the instance.
To customize the instances used as seeds when an instance joins
the cluster, pass the groupSeeds option to
the dba.createCluster() and
cluster.addInstance() commands. Seed
instances are contacted when a new instance joins a cluster and
used to provide data to the new instance. The addresses are
specified as a comma separated list such as
host1:port1,host2:port2.
This configures the
group_replication_group_seeds
system variable.
For more information see the documentation of the system variables configured by these AdminAPI options.
If an instance leaves the cluster, for example because it lost
connection, and for some reason it could not automatically
rejoin the cluster, it might be necessary to rejoin it to the
cluster at a later stage. To rejoin an instance to a cluster
issue
Cluster.rejoinInstance(instance)
If the instance has
super_read_only=ON then you
might need to confirm that AdminAPI can set
super_read_only=OFF. See
Super Read-only and Instances for more
information.
In the case where an instance has not had it's
configuration persisted (see
Persisting Settings),
upon restart the instance does not rejoin the cluster
automatically. The solution is to issue
cluster.rejoinInstance() so that the instance
is added to the cluster again and ensure the changes are
persisted. Once the InnoDB cluster configuration is persisted
to the instance's option file it rejoins the cluster
automatically.
If you are rejoining an instance which has changed in some way
then you might have to modify the instance to make the rejoin
process work correctly. For example, when you restore a MySQL Enterprise Backup
backup, the server_uuid
changes. Attempting to rejoin such an instance fails because
InnoDB cluster instances are identified by the
server_uuid variable. In such a
situation, information about the instance's old
server_uuid must be removed
from the InnoDB cluster metadata and then a
Cluster.rescan()server_uuid. For example:
cluster.removeInstance("root@instanceWithOldUUID:3306", {force: true})
cluster.rescan()
In this case you must pass the force option
to the
Cluster.removeInstance()
If an instance (or instances) fail, then a cluster can lose its quorum, which is the ability to vote in a new primary. This can happen when a there is a failure of enough instances that there is no longer a majority of the instances which make up the cluster to vote on Group Replication operations. When a cluster loses quorum you can no longer process write transactions with the cluster, or change the cluster's topology, for example by adding, rejoining, or removing instances. However if you have an instance online which contains the InnoDB cluster metadata, it is possible to restore a cluster with quorum. This assumes you can connect to an instance that contains the InnoDB cluster metadata, and that instance can contact the other instances you want to use to restore the cluster.
This operation is potentially dangerous because it can create a split-brain scenario if incorrectly used and should be considered a last resort. Make absolutely sure that there are no partitions of this group that are still operating somewhere in the network, but not accessible from your location.
Connect to an instance which contains the cluster's metadata,
then use the
Cluster.forceQuorumUsingPartitionOf(instance)instance, and then all the instances
that are ONLINE from the point of view of the
given instance definition are added to the restored cluster.
mysql-js> cluster.forceQuorumUsingPartitionOf("ic@ic-1:3306")
Restoring replicaset 'default' from loss of quorum, by using the partition composed of [ic@ic-1:3306]
Please provide the password for 'ic@ic-1:3306': ******
Restoring the InnoDB cluster ...
The InnoDB cluster was successfully restored using the partition from the instance 'ic@ic-1:3306'.
WARNING: To avoid a split-brain scenario, ensure that all other members of the replicaset
are removed or joined back to the group that was restored.
In the event that an instance is not automatically added to the
cluster, for example if its settings were not persisted, use
Cluster.rejoinInstance()
The restored cluster might not, and does not have to, consist of all of the original instances which made up the cluster. For example, if the original cluster consisted of the following five instances:
ic-1ic-2ic-3ic-4ic-5
and the cluster experiences a split-brain scenario, with
ic-1, ic-2, and
ic-3 forming one partition while
ic-4 and ic-5 form another
partition. If you connect to ic-1 and issue
Cluster.forceQuorumUsingPartitionOf('ic@ic-1:3306')
ic-1ic-2ic-3
because ic-1 sees ic-2 and
ic-3 as ONLINE and does
not see ic-4 and ic-5.
If your cluster suffers from a complete outage, you can ensure
it is reconfigured correctly using
dba.rebootClusterFromCompleteOutage(). This
operation takes the instance which MySQL Shell is currently
connected to and uses its metadata to recover the cluster. In
the event that a cluster's instances have completely stopped,
the instances must be started and only then can the cluster be
started. For example if the machine a sandbox cluster was
running on has been restarted, and the instances were at ports
3310, 3320 and 3330, issue:
mysql-js>dba.startSandboxInstance(3310)mysql-js>dba.startSandboxInstance(3320)mysql-js>dba.startSandboxInstance(3330)
This ensures the sandbox instances are running. In the case of a
production deployment you would have to start the instances
outside of MySQL Shell. Once the instances have started, you
need to connect to an instance with the GTID superset, which
means the instance which had applied the most transaction before
the outage. If you are unsure which instance contains the GTID
superset, connect to any instance and follow the interactive
messages from the
dba.rebootClusterFromCompleteOutage(), which
detects if the instance you are connected to contains the GTID
superset. Reboot the cluster by issuing:
mysql-js> var cluster = dba.rebootClusterFromCompleteOutage();
The dba.rebootClusterFromCompleteOutage()
operation then follows these steps to ensure the cluster is
correctly reconfigured:
The InnoDB cluster metadata found on the instance which MySQL Shell is currently connected to is checked to see if it contains the GTID superset, in other words the transactions applied by the cluster. If the currently connected instance does not contain the GTID superset, the operation aborts with that information. See the subsequent paragraphs for more information.
If the instance contains the GTID superset, the cluster is recovered based on the metadata of the instance.
Assuming you are running MySQL Shell in interactive mode, a wizard is run that checks which instances of the cluster are currently reachable and asks if you want to rejoin any discovered instances to the rebooted cluster.
Similarly, in interactive mode the wizard also detects instances which are currently not reachable and asks if you would like to remove such instances from the rebooted cluster.
If you are not using MySQL Shell's interactive mode, you
can use the rejoinInstances and
removeInstances options to manually configure
instances which should be joined or removed during the reboot of
the cluster.
If you encounter an error such as The active session
instance isn't the most updated in comparison with the ONLINE
instances of the Cluster's metadata. then the
instance you are connected to does not have the GTID superset of
transactions applied by the cluster. In this situation, connect
MySQL Shell to the instance suggested in the error message and
issue dba.rebootClusterFromCompleteOutage()
from that instance.
To manually detect which instance has the GTID superset rather
than using the interactive wizard, check the
gtid_executed variable on
each instance. For example issue:
mysql-sql> SHOW VARIABLES LIKE 'gtid_executed';The instance which has applied the largest GTID set of transactions contains the GTID superset.
If this process fails, and the cluster metadata has become badly
corrupted, you might need to drop the metadata and create the
cluster again from scratch. You can drop the cluster metadata
using dba.dropMetadataSchema().
The dba.dropMetadataSchema() method should
only be used as a last resort, when it is not possible to
restore the cluster. It cannot be undone.
If you make configuration changes to a cluster outside of the
AdminAPI commands, for example by changing an
instance's configuration manually to resolve configuration
issues or after the loss of an instance, you need to update the
InnoDB cluster metadata so that it matches the current
configuration of instances. In these cases, use the
Cluster.rescan()Cluster.rescan()
The syntax of the command is
Cluster.rescan([options])options dictionary supports the
following:
interactive: boolean value used to disable or enable the wizards in the command execution. Controls whether prompts and confirmations are provided. The default value is equal to MySQL Shell wizard mode, specified byshell.options.useWizards.addInstances: list with the connection data of the new active instances to add to the metadata, or “auto” to automatically add missing instances to the metadata. The value “auto” is case-insensitive.Instances specified in the list are added to the metadata, without prompting for confirmation
In interactive mode, you are prompted to confirm the addition of newly discovered instances that are not included in the
addInstancesoptionIn non-interactive mode, newly discovered instances that are not included in the
addInstancesoption are reported in the output, but you are not prompted to add them
removeInstances: list with the connection data of the obsolete instances to remove from the metadata, or “auto” to automatically remove obsolete instances from the metadata.Instances specified in the list are removed from the metadata, without prompting for confirmation
In interactive mode, you are prompted to confirm the removal of obsolete instances that are not included in the
removeInstancesoptionIn non-interactive mode, obsolete instances that are not included in the
removeInstancesoption are reported in the output but you are not prompted to remove them
updateTopologyMode: boolean value used to indicate if the topology mode (single-primary or multi-primary) in the metadata should be updated (true) or not (false) to match the one being used by the cluster. By default, the metadata is not updated (false).If the value is
truethen the InnoDB cluster metadata is compared to the current mode being used by Group Replication, and the metadata is updated if necessary. Use this option to update the metadata after making changes to the topology mode of your cluster outside of AdminAPI.If the value is
falsethen InnoDB cluster metadata about the cluster's topology mode is not updated even if it is different from the topology used by the cluster's Group Replication groupIf the option is not specified and the topology mode in the metadata is different from the topology used by the cluster's Group Replication group, then:
In interactive mode, you are prompted to confirm the update of the topology mode in the metadata
In non-interactive mode, if there is a difference between the topology used by the cluster's Group Replication group and the InnoDB cluster metadata, it is reported and no changes are made to the metadata
When the metadata topology mode is updated to match the Group Replication mode, the auto-increment settings on all instances are updated as described at InnoDB cluster and Auto-increment.
The cluster.checkInstanceState() function can
be used to verify the existing data on an instance does not
prevent it from joining a cluster. This process works by
validating the instance's global transaction identifier (GTID)
state compared to the GTIDs already processed by the cluster.
For more information on GTIDs see
Section 17.1.3.1, “GTID Format and Storage”. This check enables
you to determine if an instance which has processed transactions
can be added to the cluster.
The following demonstrates issuing this in a running MySQL Shell:
mysql-js> cluster.checkInstanceState('ic@ic-4:3306')
The output of this function can be one of the following:
OK new: the instance has not executed any GTID transactions, therefore it cannot conflict with the GTIDs executed by the cluster
OK recoverable: the instance has executed GTIDs which do not conflict with the executed GTIDs of the cluster seed instances
ERROR diverged: the instance has executed GTIDs which diverge with the executed GTIDs of the cluster seed instances
ERROR lost_transactions: the instance has more executed GTIDs than the executed GTIDs of the cluster seed instances
Instances with an OK status can be added to the cluster because any data on the instance is consistent with the cluster. In other words the instance being checked has not executed any transactions which conflict with the GTIDs executed by the cluster, and can be recovered to the same state as the rest of the cluster instances.
To dissolve an InnoDB cluster you connect to a read-write
instance, for example the primary in a single-primary cluster,
and use the
Cluster.dissolve()
There is no way to undo the dissolving of a cluster. To create
it again use dba.createCluster().
The
Cluster.dissolve()ONLINE or reachable. If members of a cluster
cannot be reached by the member where you issued the
Cluster.dissolve()
Forcing the dissolve operation to ignore cluster instances can result in instances which could not be reached during the dissolve operation continuing to operate, creating the risk of a split-brain situation. Only ever force a dissolve operation to ignore missing instances if you are sure there is no chance of the instance coming online again.
In interactive mode, if members of a cluster are not reachable during a dissolve operation then an interactive prompt is displayed, for example:
mysql-js> Cluster.dissolve()
In this example, the cluster consisted of three instances, one
of which was offline when dissolve was issued. The error is
caught, and you are given the choice how to proceed. In this
case the missing ic-2 instance is ignored and
the reachable members have their metadata updated.
When MySQL Shell is running in non-interactive mode, for
example when running a batch file, you can configure the
behavior of the
Cluster.dissolve()force option. To force
the dissolve operation to ignore any instances which are
unreachable, issue:
mysql-js> Cluster.dissolve({force: true})Any instances which can be reached are removed from the cluster, and any unreachable instances are ignored. The warnings in this section about forcing the removal of missing instances from a cluster apply equally to this technique of forcing the dissolve operation.
You can also use the interactive option with
the
Cluster.dissolve()
mysql-js> Cluster.dissolve({interactive: true})
The dba.gtidWaitTimeout MySQL Shell option
configures how long the
Cluster.dissolve()ONLINE. An error is issued
if the timeout is reached when waiting for cluster transactions
to be applied on any of the instances being removed, except if
force: true is used, which skips the error in that case.
After issuing cluster.dissolve(), any
variable assigned to the
Cluster
Server instances can be configured to use secure connections. For general information on using SSL with MySQL see Section 6.3, “Using Encrypted Connections”. This section explains how to configure a cluster to use SSL. An additional security possibility is to configure which servers can access the cluster, see Creating a Whitelist of Servers.
Once you have configured a cluster to use SSL you must add the
servers to the ipWhitelist.
When using dba.createCluster() to set up a
cluster, if the server instance provides SSL encryption then it
is automatically enabled on the seed instance. Pass the
memberSslMode option to the
dba.createCluster() method to specify a
different SSL mode. The SSL mode of a cluster can only be set at
the time of creation. The memberSslMode
option is a string that configures the SSL mode to be used, it
defaults to AUTO. The permitted values are
DISABLED, REQUIRED, and
AUTO. These modes are defined as:
Setting
createCluster({memberSslMode:'DISABLED'})ensures SSL encryption is disabled for the seed instance in the cluster.Setting
createCluster({memberSslMode:'REQUIRED'})then SSL encryption is enabled for the seed instance in the cluster. If it cannot be enabled an error is raised.Setting
createCluster({memberSslMode:'AUTO'})(the default) then SSL encryption is automatically enabled if the server instance supports it, or disabled if the server does not support it.
When using the commercial version of MySQL, SSL is enabled by default and you might need to configure the whitelist for all instances. See Creating a Whitelist of Servers.
When you issue the cluster.addInstance() and
cluster.rejoinInstance() commands, SSL
encryption on the instance is enabled or disabled based on the
setting found for the seed instance.
When using createCluster() with the
adoptFromGR option to adopt an existing Group
Replication group, no SSL settings are changed on the adopted
cluster:
memberSslModecannot be used withadoptFromGR.If the SSL settings of the adopted cluster are different from the ones supported by the MySQL Shell, in other words SSL for Group Replication recovery and Group Communication, both settings are not modified. This means you are not be able to add new instances to the cluster, unless you change the settings manually for the adopted cluster.
MySQL Shell always enables or disables SSL for the cluster for
both Group Replication recovery and Group Communication, see
Section 18.5.2, “Group Replication Secure Socket Layer (SSL) Support”.
A verification is performed and an error issued in case those
settings are different for the seed instance (for example as the
result of a dba.createCluster() using
adoptFromGR) when adding a new instance to
the cluster. SSL encryption must be enabled or disabled for all
instances in the cluster. Verifications are performed to ensure
that this invariant holds when adding a new instance to the
cluster.
The deploySandboxInstance() command attempts
to deploy sandbox instances with SSL encryption support by
default. If it is not possible, the server instance is deployed
without SSL support. Use the ignoreSslError
option set to false to ensure that sandbox instances are
deployed with SSL support, issuing an error if SSL support
cannot be provided. When ignoreSslError is
true, which is the default, no error is issued during the
operation if the SSL support cannot be provided and the server
instance is deployed without SSL support.
When using a cluster's createCluster(),
addInstance(), and
rejoinInstance() methods you can optionally
specify a list of approved servers that belong to the cluster,
referred to as a whitelist. By specifying the whitelist
explicitly in this way you can increase the security of your
cluster because only servers in the whitelist can connect to the
cluster.
Using the ipWhitelist option configures the
group_replication_ip_whitelist
system variable on the instance. By default, if not specified
explicitly, the whitelist is automatically set to the private
network addresses that the server has network interfaces on. To
configure the whitelist, specify the servers to add with the
ipWhitelist option when using the method. IP
addresses must be specified in IPv4 format.
Pass the servers as a comma separated list, surrounded by
quotes. For example:
mysql-js> cluster.addInstance("ic@ic-3:3306", {ipWhitelist: "203.0.113.0/24, 198.51.100.110"})
This configures the instance to only accept connections from
servers at addresses 203.0.113.0/24 and
198.51.100.110. The whitelist can also
include host names, which are resolved only when a connection
request is made by another server.
Host names are inherently less secure than IP addresses in a whitelist. MySQL carries out FCrDNS verification, which provides a good level of protection, but can be compromised by certain types of attack. Specify host names in your whitelist only when strictly necessary, and ensure that all components used for name resolution, such as DNS servers, are maintained under your control. You can also implement name resolution locally using the hosts file, to avoid the use of external components.
You can automate cluster configuration with scripts, which can be run using MySQL Shell. For example:
shell> mysqlsh -f setup-innodb-cluster.js
Any command line options specified after the script file name
are passed to the script and not to
MySQL Shell. You can access those options using the
os.argv array in JavaScript, or the
sys.argv array in Python. In both cases,
the first option picked up in the array is the script name.
The contents of an example script file is shown here:
print('InnoDB cluster sandbox set up\n');
print('==================================\n');
print('Setting up a MySQL InnoDB cluster with 3 MySQL Server sandbox instances.\n');
print('The instances will be installed in ~/mysql-sandboxes.\n');
print('They will run on ports 3310, 3320 and 3330.\n\n');
var dbPass = shell.prompt('Please enter a password for the MySQL root account: ', {type:"password"});
try {
print('\nDeploying the sandbox instances.');
dba.deploySandboxInstance(3310, {password: dbPass});
print('.');
dba.deploySandboxInstance(3320, {password: dbPass});
print('.');
dba.deploySandboxInstance(3330, {password: dbPass});
print('.\nSandbox instances deployed successfully.\n\n');
print('Setting up InnoDB cluster...\n');
shell.connect('root@localhost:3310', dbPass);
var cluster = dba.createCluster("prodCluster");
print('Adding instances to the cluster.');
cluster.addInstance({user: "root", host: "localhost", port: 3320, password: dbPass});
print('.');
cluster.addInstance({user: "root", host: "localhost", port: 3330, password: dbPass});
print('.\nInstances successfully added to the cluster.');
print('\nInnoDB cluster deployed successfully.\n');
} catch(e) {
print('\nThe InnoDB cluster could not be created.\n\nError: ' +
+ e.message + '\n');
}
You can optionally configure how a single-primary cluster elects
a new primary, for example to prefer one instance as the new
primary to fail over to. Use the memberWeight
option and pass it to the dba.createCluster()
and Cluster.addInstance() methods when
creating your cluster. The memberWeight
option accepts an integer value between 0 and 100, which is a
percentage weight for automatic primary election on failover.
When an instance has a higher precentage number set by
memberWeight, it is more likely to be elected
as primary in a single-primary cluster. When a primary election
takes place, if multiple instances have the same
memberWeight value, the instances are then
prioritized based on their server UUID in lexicographical order
(the lowest) and by picking the first one.
Setting the value of memberWeight configures
the
group_replication_member_weight
system variable on the instance. Group Replication limits the
value range from 0 to 100, automatically adjusting it if a
higher or lower value is provided. Group Replication uses a
default value of 50 if no value is provided. See
Section 18.1.3.1, “Single-Primary Mode” for more
information.
For example to configure a cluster where ic-3
is the preferred instance to fail over to in the event that
ic-1, the current primary, leaves the cluster
unexpectedly use memberWeight as follows:
dba.createCluster('cluster1', {memberWeight:35})
var mycluster = dba.getCluster()
mycluster.addInstance('ic@ic2', {memberWeight:25})
mycluster.addInstance('ic@ic3', {memberWeight:50})
Group Replication provides the ability to specify the failover
guarantees (eventual or “read your writes”) if a
primary failover happens in single-primary mode (see
Section 18.4.2.2, “Configuring Transaction Consistency Guarantees”).
You can configure the failover guarantees of an InnoDB cluster
at creation by passing the consistency option
(prior to version 8.0.16 this option was the
failoverConsistency option, which is now
deprecated) to the dba.createCluster()
operation, which configures the
group_replication_consistency
system variable on the seed instance. This option defines the
behavior of a new fencing mechanism used when a new primary is
elected in a single-primary group. The fencing restricts
connections from writing and reading from the new primary until
it has applied any pending backlog of changes that came from the
old primary (sometimes referred to as “read your
writes”). While the fencing mechanism is in place,
applications effectively do not see time going backward for a
short period of time while any backlog is applied. This ensures
that applications do not read stale information from the newly
elected primary.
The consistency option is only supported if
the target MySQL server version is 8.0.14 or later, and
instances added to a cluster which has been configured with the
consistency option are automatically
configured to have
group_replication_consistency
the same on all cluster members that have support for the
option. The variable default value is controlled by Group
Replication and is EVENTUAL, change the
consistency option to
BEFORE_ON_PRIMARY_FAILOVER to enable the
fencing mechanism. Alternatively use
consistency=0 for EVENTUAL
and consistency=1 for
BEFORE_ON_PRIMARY_FAILOVER.
Using the consistency option on a
multi-primary InnoDB cluster has no effect but is allowed
because the cluster can later be changed into single-primary
mode with the
Cluster.switchToSinglePrimaryMode()
By default, an InnoDB cluster runs in single-primary mode, where the cluster has one primary server that accepts read and write queries (R/W), and all of the remaining instances in the cluster accept only read queries (R/O). When you configure a cluster to run in multi-primary mode, all of the instances in the cluster are primaries, which means that they accept both read and write queries (R/W). If a cluster has all of its instances running MySQL server version 8.0.15 or later, you can make changes to the topology of the cluster while the cluster is online. In previous versions it was necessary to completely dissolve and re-create the cluster to make the configuration changes. This uses the group action coordinator exposed through the UDFs described at Section 18.4.1, “Configuring an Online Group”, and as such you should observe the rules for configuring online groups.
multi-primary mode is considered an advanced mode
Usually a single-primary cluster elects a new primary when the
current primary leaves the cluster unexpectedly, for example due
to an unexpected halt. The election process is normally used to
choose which of the current secondaries becomes the new primary.
To override the election process and force a specific server to
become the new primary, use the
Cluster.setPrimaryInstance(instance)instance specifies
the connection to the instance which should become the new
primary. This enables you to configure the underlying Group
Replication group to choose a specific instance as the new
primary, bypassing the election process.
You can change the mode (sometimes described as the topology) which a cluster is running in between single-primary and multi-primary using the following operations:
Cluster.switchToMultiPrimaryMode()Cluster.switchToSinglePrimaryMode([instance])instanceis specified, it becomes the primary and all the other instances become secondaries. Ifinstanceis not specified, the new primary is the instance with the highest member weight (and the lowest UUID in case of a tie on member weight).
You can check and modify the settings in place for an InnoDB cluster while the instances are online. To check the current settings of a cluster, use the following operation:
Cluster.options()allcan also be specified to include information about all Group Replication system variables in the output.
You can configure the options of an InnoDB cluster at a cluster level or instance level, while instances remain online. This avoids the need to remove, reconfigure and then again add the instance to change InnoDB cluster options. Use the following operations:
Cluster.setOption(option,value)clusterName.Cluster.setInstanceOption(instance,option,value)
The way which you use InnoDB cluster options with the operations listed depends on whether the option can be changed to be the same on all instances or not. These options are changeable at both the cluster (all instances) and per instance level:
exitStateActionmemberWeight
This option is changeable at the per instance level only:
label
These options are changeable at the cluster level only:
consistencyexpelTimeoutclusterName
When you are using an instance as part of an InnoDB cluster,
the auto_increment_increment
and auto_increment_offset
variables are configured to avoid the possibility of auto
increment collisions for multi-primary clusters up to a size of
9 (the maximum supported size of a Group Replication group). The
logic used to configure these variables can be summarized as:
If the group is running in single-primary mode, then set
auto_increment_incrementto 1 andauto_increment_offsetto 2.If the group is running in multi-primary mode, then when the cluster has 7 instances or less set
auto_increment_incrementto 7 andauto_increment_offsetto 1 +server_id% 7. If a multi-primary cluster has 8 or more instances setauto_increment_incrementto the number of instances andauto_increment_offsetto 1 +server_id% the number of instances.
This section describes the known limitations of InnoDB cluster. As InnoDB cluster uses Group Replication, you should also be aware of its limitations, see Section 18.9.2, “Group Replication Limitations”.
If a session type is not specified when creating the global session, MySQL Shell provides automatic protocol detection which attempts to first create a NodeSession and if that fails it tries to create a ClassicSession. With an InnoDB cluster that consists of three server instances, where there is one read-write port and two read-only ports, this can cause MySQL Shell to only connect to one of the read-only instances. Therefore it is recommended to always specify the session type when creating the global session.
When adding non-sandbox server instances (instances which you have configured manually rather than using
dba.deploySandboxInstance()) to a cluster, MySQL Shell is not able to persist any configuration changes in the instance's configuration file. This leads to one or both of the following scenarios:The Group Replication configuration is not persisted in the instance's configuration file and upon restart the instance does not rejoin the cluster.
The instance is not valid for cluster usage. Although the instance can be verified with
dba.checkInstanceConfiguration(), and MySQL Shell makes the required configuration changes in order to make the instance ready for cluster usage, those changes are not persisted in the configuration file and so are lost once a restart happens.
If only
ahappens, the instance does not rejoin the cluster after a restart.If
balso happens, and you observe that the instance did not rejoin the cluster after a restart, you cannot use the recommendeddba.rebootClusterFromCompleteOutage()in this situation to get the cluster back online. This is because the instance loses any configuration changes made by MySQL Shell, and because they were not persisted, the instance reverts to the previous state before being configured for the cluster. This causes Group Replication to stop responding, and eventually the command times out.To avoid this problem it is strongly recommended to use
dba.configureInstance()before adding instances to a cluster in order to persist the configuration changes.The use of the
--defaults-extra-fileoption to specify an option file is not supported by InnoDB cluster server instances. InnoDB cluster only supports a single option file on instances and no extra option files are supported. Therefore for any operation working with the instance's option file the main one should be specified. If you want to use multiple option files you have to configure the files manually and make sure they are updated correctly considering the precedence rules of the use of multiple option files and ensuring that the desired settings are not incorrectly overwritten by options in an extra unrecognized option file.Attempting to use instances with a host name that resolves to an IP address which does not match a real network interface fails with an error that This instance reports its own address as
the hostname. This is not supported by the Group Replication communication layer. On Debian based instances this means instances cannot use addresses such asuser@localhostbecause localhost resolves to a non-existent IP (such as 127.0.1.1). This impacts on using a sandbox deployment, which usually uses local instances on a single machine.A workaround is to configure the
report_hostsystem variable on each instance to use the actual IP address of your machine. Retrieve the IP of your machine and addreport_host=to theIP of your machinemy.cnffile of each instance. You need to ensure the instances are then restarted to make the change.